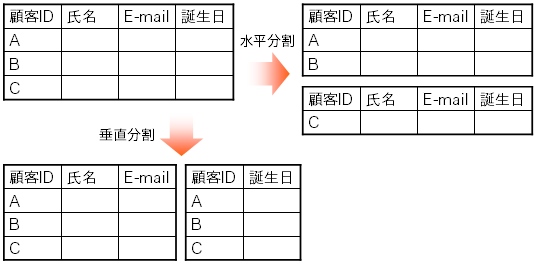
図1: リレーショナルDBでのデータ分割
Last-updated: January 5, 2010
注: このページの文章は以下の記事の元原稿です。首藤一幸, "スケールアウトの技術", クラウドの技術, pp.88-101, (株)アスキー・メディアワークス, ISBN978-4-04-868064-6, 2009年 11月 6日
首藤一幸, "スケールアウトの技術", UNIX magazine 2009年 4月号, pp.78-91, (株)アスキー・メディアワークス, 2009年 3月 18日
データベースに求められる性能を試算したところ、 十台、百台…数万台のサーバが必要になった。 クラウドを構築する側はこういう問題に直面し、解決しようとしてきた。 台数に比例した性能を引き出すこと、つまりscale outは、数台であっても難しい。 本稿では、それ以上の規模から成る分散システム、 特に分散データベースをscale outさせるための技術を説明する。
1つのデータベースを複数台のサーバで組む必要があるとする。 理由は次のいずれかであろう。
アクセス性能と容量の両方を狙うためには、 複数台のサーバでデータを分担して持つ必要がある。 データをサーバ群に分けて分担させる際の方針にも、次の通りいくつかある。
表ごとというのは、例えば、顧客の表、商品の表、取り引きの表を それぞれ別のサーバに持たせることを指す。 これによって、それぞれの表のデータと、それらに対するアクセスを サーバ群に分散させることができる。 しかし往々にして、表によってサイズやアクセスの量はまちまちである。 例えば、商品はせいぜい数万種類であるが、顧客は数百万人に達する、というように、 行、キーの数に偏りがあることの方が普通である。 なので、サーバでうまく負荷を分散するためには、 大きな表やアクセスが集中する表を複数のサーバに分散させることが必要となってくる。
図1: リレーショナルDBでのデータ分割
リレーショナルDBの場合、表は行方向(縦)と列方向(横)という2次元の表なので、 分割の方針にも、行ごとに分割する水平分割と、列ごとの垂直分割の2通りがある (図1)。 垂直分割とは、1つの行を分割すること、 例えば1人の顧客についての情報を住所と所属組織で別の表に持たせることにあたる。 これはつまり、複数の表への分割である。 垂直分割は、表の正規化や、セキュリティ等必然的な理由で行われる分割であり、 また、いくつに分割できるかもたかが知れている。 アクセス性能や容量を稼ぐ目的にはそれほど向かないため、 以降では水平分割、キーごとの分割について考える。
表が保持する件数に応じて増えるのは行やキーの数である。 行ごと、キーごとに分割することで、 分割数を大きくでき、また、分割の割り合いも調整できる。 つまり、100台に分割、サーバの性能を考慮して8対2に分割、 ということができる可能性がある。 垂直分割ではそうはいかない。
リレーショナルDBで水平分割を行う際、どの行をどのサーバに分担させるかを どうやって决めるか? ランダムに决めたり、最初の行は1番サーバ、次の行は2番サーバ、というように 决めたのでは、せっかくサーバを増やしてもアクセス性能を稼げないということになる。 つまり、アクセスしたい行をどのサーバが保持しているか事前にはわからないため、 全サーバに対して問い合わせなければならず、 それでは何台集めても1台並のアクセス性能しか得られない。 そこで、ある列を分割キー(partition key)として指定して、 その列の値に応じて何らかの規則に従って担当するサーバを决める。 これによって、データベースへの問い合わせが分割キーについての条件を含む限りは、 問い合わせの内容から担当するサーバを割り出すことができ、 一部のサーバにさえ問い合わせれば済むようになる。 key-valueストア(コラム参照)の場合は、 キーに応じて担当サーバを决め、 その担当サーバにキーと値を保持させる、ということになる。
キーから担当サーバを决める規則はいくつか考えられる。 例えば、あらかじめキーと担当サーバの対応表を用意しておく方法、 キーの範囲ごとに担当サーバを分ける方法がある。 具体的には、 前者は、顧客の住所が「東京都」なら1番サーバ、それ以外なら2番サーバ、 といった分け方、 後者は、顧客IDが0から10000までは1番サーバ…といった分け方である。
対応表や範囲に基づいたのではうまくいかない場合が多々ある。 キーが様々な値をとる場合、対応表では対応しきれない。 具体的には、ウェブのURLをキーとする場合を想像して欲しい。 範囲に基づく分割ではサーバ間でデータ量を均等に保つことが難しい。 事前に全データが揃っているならば、 サーバ間で均等になるように担当範囲を調整できるが、 データが増えていく状況、特にどういうデータがやってくるか判らない状況では、 それは難しい。
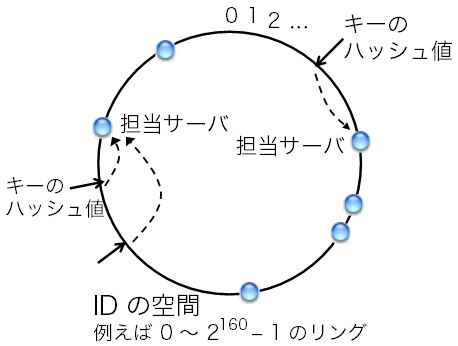
ここでよく行われるのが、キーのハッシュ値に基づいた担当サーバ决め、である。 まず、サーバが4台であれば、キーに対して0から3までの4通りの値を返す ハッシュ関数を用意する。 キーに対するハッシュ関数の計算結果、つまりハッシュ値が0であれば0番サーバ、 1であれば1番サーバ、というように担当サーバを决めるのである。 こういったハッシュ関数はたいてい次のように構成する。
担当サーバ番号 = H(キー) mod NここでHはMD5やSHA-1といった暗号学的ハッシュ関数、 modは割り算の余りを返す剰余算、 Nはサーバの台数を表す。 暗号学的ハッシュ関数は、入力されたビット列に対して 0〜2128や2160といった範囲の値を返す。 その値を、剰余算で、 例えばmod 4であれば0、1、2、3という4通りの値に変換して、 担当サーバ番号とする。 暗号学的ハッシュ関数は様々な入力に対してまんべんなく様々な値を返すため、 それぞれのサーバが担当するデータの量はだいたい均等になる。
ここまでで、担当サーバ决めの問題は解決したように見えるかもしれない。 しかし実は、ここまで説明した担当サーバ决め手法には、 サーバ数の増減に弱いという限界がある。
ここで、性能や容量を上げるためにサーバの台数を増やす、 または、管理作業のために減らすという状況を考える。 さきほどのハッシュ関数を用いる方法では、サーバの台数Nが変わると ほとんどのキーに対する担当サーバが変わってしまう。 例えば関数Hが返す値が1234だった場合、Nが4から5に増えると、 担当サーバ番号は1234 mod 4 = 2から1234 mod 5 = 4に変わってしまう。 サーバの台数Nが1台増えてN+1となると、 割り合いにして全データのN/(N+1)について担当サーバが変わってしまう。 4台を5台に増やすと全データの80%、9台を10台に増やすと全データの90%について 担当サーバが変わる計算である。 全サーバを活かして全データを保持し続けるためには、 データの再配分が必要となる。 全データの80%や90%という量をサーバ間で再配分しなければならない。 データ量が多い場合、これは非常に大変であるか、ほとんど不可能である。
また、人手で台数を増減させずとも、 サーバの台数が多ければ故障が日常茶飯事となる。 例えば、平均故障間隔(MTBF)が15,000時間、つまり1年8〜9ヶ月という PCがあった場合、 その1台が24時間故障なしで稼働し続ける確率は99.8%であるが、 これが10台となると98.4%、100台では85.2%、500台では44.9%となり、 24時間中に1台は壊れる公算の方が高いことになる。 わずか10台であっても、44日間で故障が起きない確率は49.5%と5割を切ってくる。
つまり、サーバの台数が増えるほど、 増減はあるものという前提を置かざるを得なくなってくる。 逆に言うと、台数の増減に耐える担当サーバ决め手法がないことには、 サーバの台数を増やせない。 そこで、サーバの増減に耐える手法として考えられたのが consistent hashingである。
さきほどのH(キー) mod Nというハッシュ関数を使うと、 台数の増減に対してほとんどのキーに対する担当サーバが変わってしまった。 それに対して、ある種の手順で担当サーバを决めると、 台数が増減した場合でも担当サーバが変わるのは全キーの1 / N程度で済む。 すると、再配分するデータも少なくて済むし、 仮に再配分を行わなかったとしても担当の変わらなかった大多数のデータは 有効なままとなる。 このような性質を満たす担当サーバ决め手法をconsistent hashingと言う。 これはもともと、複数台でウェブのキャッシュサーバを構成する状況を想定して 考え出され、1997年に論文で発表された。 キャッシュサーバの場合、キーはウェブのURLとなる。
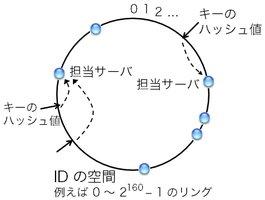
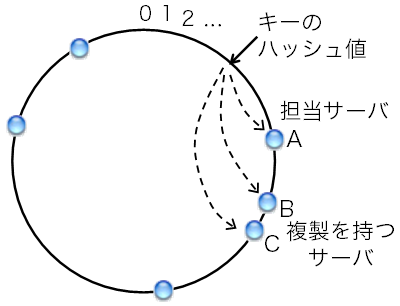
図2: consistent hashingの条件を満たす担当サーバ决め手法の例(時計回り方式)
この条件を見たす手順には、例えば次のようなものがある。 0〜2160-1の整数値をとるIDの空間を考える。 これはつまり暗号学的ハッシュ関数SHA-1が返す値の範囲である。 SHA-1ではなくてMD5を使う場合は0〜2128-1とすればよい。 図2の通り、最大値2160-1の次の値は0となるようなリングを想定する。 ここで重要なのは、キーとサーバの両方に対して、 0〜2160-1の範囲からIDを割り振るという点である。 キーに対してはSHA-1の計算結果をIDとして割り振ればよい。 サーバに対しては、例えばIPアドレスのSHA-1ハッシュ値を割り振るか、 または任意の値を割り振るという方法もある。
キーの担当サーバは次の手順で决める。 図2の通り、キーのIDからID空間を時計回りに辿り、 最初に行きあたったサーバを担当サーバとする。
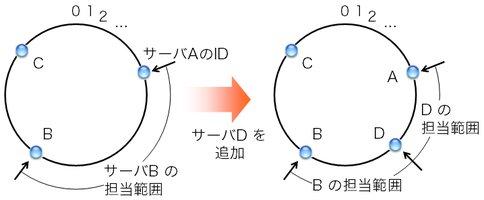
図3: サーバが増えた場合の担当範囲の変化(時計回り方式の場合)
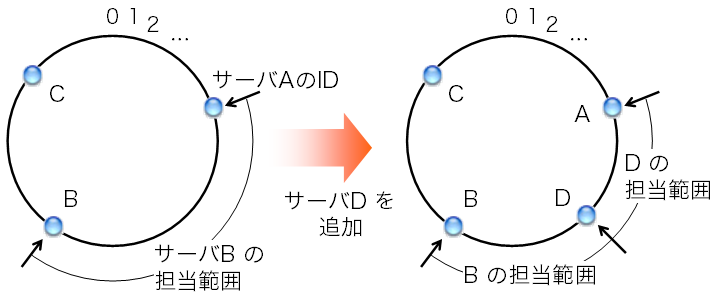
この手順はconsistent hashingの条件を満たす。 つまり、サーバが増減しても、 担当サーバが変わるキーは全キーの1 / N程度で済む。 図3のように、サーバA、B、Cでキーを分担していたところに サーバDを追加するという状況を考える。 すると、サーバBが担当していた範囲の一部がサーバDの担当となる。 この際、サーバAとCの担当範囲は変わらず、Dが追加されたことによる影響はない。 9台に1台追加する状況を考えると、 H(キー) mod Nの方法ではキーの90%について 担当サーバが変わってしまったところ、 この方法では平均して10%程度で済む。
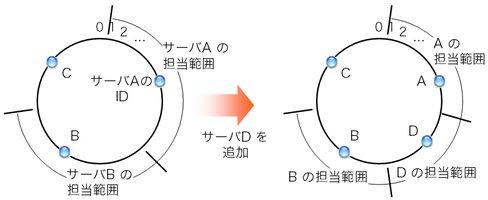
図4: サーバが増えた場合の担当範囲の変化(最近値方式の場合)
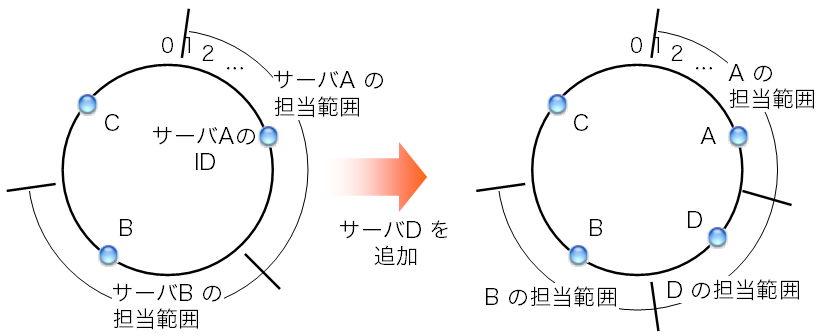
consistent hashingの条件を満たす担当サーバ决め手法は、 上で説明した時計回りの方法だけではない。 図4は、キーのIDから数値的に最も近いIDを持つサーバを担当サーバとする、 という手法を示している。 これもconsistent hashingの条件を満たしている。 ただし、サーバを追加・除去した場合に担当範囲が変わるサーバが、 時計回りの方法(図3)ではサーバB 1台、 最近値の方法(図4)ではサーバAとBの2台、といった若干の違いが出てくる。
また、実のところ、consistent hashingのために リング状のID空間が必須というわけでもない。 peer-to-peer方面の技術、分散ハッシュ表の一方式であるKademliaは、 IDとIDの間でビットごとのXOR(排他的論理和)を計算し、それをID間の距離とし、 距離が最も近いサーバを担当サーバとする。 ID 3と4は、リング上では距離1であり近いが、 XORに基づく距離は011 XOR 100 = 111 (2進数) = 7 (10進数)となる。 これはリングとは別種の空間である。 同じく分散ハッシュ表の一方式であるCANの場合、 n次元ユークリッド空間上にサーバごとの担当領域を定め、 サーバの追加時には領域を割譲し、除去時には他のサーバの領域へ併合する。
暗号学的ハッシュ関数Hの性質が良くて計算結果がうまくばらつく限り、 H(キー) mod Nの方法では、 サーバごとの担当キー数はおよそ均等になる。 では、consistent hashingではどうか? サーバのIDとして恣意的な値ではなく乱数やハッシュ値を使い、 キーも偏りなくやってくるならば、高い確率で、ひどい偏りは生じない。 逆に、サーバ間で均等に担当するのではなく、 そもそもサーバの性能に差があって担当するキーの数に差を付けたい場合には、 virtual nodeという手法がある。 つまり、1台のサーバに複数のIDを振って、複数台分の領域を担当させるのである。
やってくるキーに偏りがある場合はどうするか? 特定のサーバばかりが多数のキーを持つことになりかねない。 これに対しては決定的な手法があるわけではないが、 動的にサーバの担当領域を調整したり、virtual nodeを増減させたり、 といった方法が研究、提案されてきている。
続いて、数十台、数百台…またはそれ以上のサーバで 分散データベースを構成することを見据えて、 システム構成を考えていく。 以下で名前を挙げるソフトウェアが必ずしも consistent hashingを採用しているわけではないことに注意されたい。
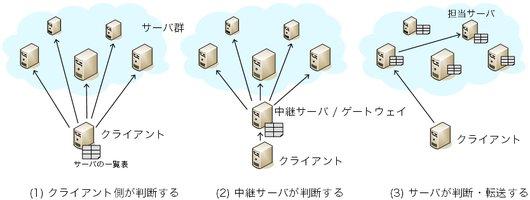
図5: キーごとの担当サーバをどのコンピュータが判断するか
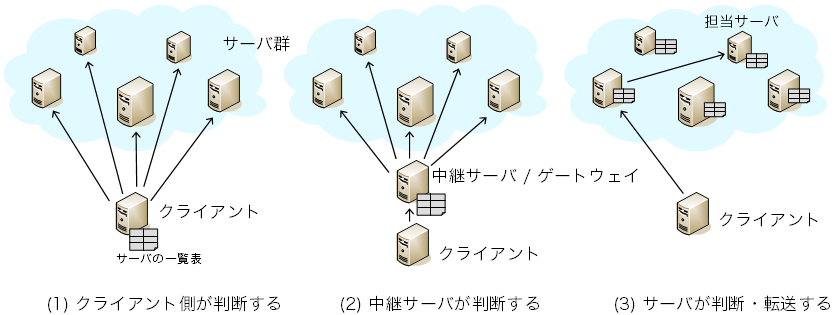
構成には、キーの担当サーバをどのコンピュータに判断させるかによって、 何通りかの選択肢がある。 代表的には次の方法がある。 図5にそれぞれの構成を示す。 それぞれに得失があり、どれを選ぶかはエンジニアリングの問題である。
(1)は、データベースにアクセスする側のソフトウェア、 つまりクライアントが自身で判断する方法である。 例えばmemcached(コラム参照)の場合、 memcachedにアクセスするために使うライブラリが キーごとの担当サーバを判断してアクセス先を决める。 そのためには、クライアント側ライブラリが、 全サーバについてのキー担当範囲と通信のためのアドレスを把握しておく必要がある。 具体的には、サーバのIDとIPアドレス・ポート番号を並べた サーバ一覧表を持つことになる。 サーバ一覧表は、人手で設定ファイルとして用意することが一般的である。 しかしそれではクライアントの台数が増えた場合に準備が大変なので、 クライアント側ライブラリが自動的に一覧表を取得するようなソフトウェアもある。 ObjectGridではCatalogサービスから、 ROMAでは、あらかじめお互いを把握しているサーバ群から一覧表を取得する。
(2)は、クライアントから受けたアクセス要求をサーバに対して中継する 中継サーバを用意し、その中継サーバがサーバ一覧表を持つ方法である。 この方法では中継サーバだけがサーバ一覧表を持てば済み、 クライアントごとの準備を省ける。 ただし、アクセスごとに中継の時間が若干かかるようになることと、 クライアントが増えた場合に中継サーバが性能のボトルネックに なりかねないことが難点である。 もっとも、中継サーバの台数を増やしてアクセス性能を稼ぐという手もある。 中継サーバを増やすくらいならデータを持つサーバ自身を 中継サーバにしてしまえばよい、と考えると、次の(3)の方法となる。
(3)は、データを保持するサーバ自身がサーバ一覧表を維持する方法である。 これによって中継サーバは不要となり、 サーバの台数、目一杯までアクセス性能を稼ぐことが可能となる。 全サーバで一覧表を維持するためには、 サーバ群を把握してその追加・除去をサーバ群に通知する 管理サーバのようなものを置く方法(例: Flare)や、 それは置かず、サーバ間で通知し合う方法(例: Dynamo)がある。 いずれにせよ、そのための通信は必要であり、 通信の回数や一覧表のサイズは台数が増えるに従って大きなものとなる。 アクセス性能がボトルネックにならないのなら、 少数の中継サーバを別に設けて、それらの上でだけ一覧表を維持する、 つまり(2)を選ぶのも良い選択かもしれない。
どの方法を選ぶかはエンジニアリングの問題であり、 ソフトウェア(コラム参照)により様々である。 memcached、ObjectGrid、ROMAは(1)、Dynamoは(1)と(3)を選択可能、 kumofsは(2)、Flareは(2)と(3)を選択可能となっている。
サーバの台数が増えると故障が日常茶飯事となるので、 あるキーについて、担当サーバだけでなく 他のサーバにもデータの複製を持たせておくことが重要となる。 そうすることで、担当サーバが前触れなく故障した場合でも 他のサーバから複製を取得できる。
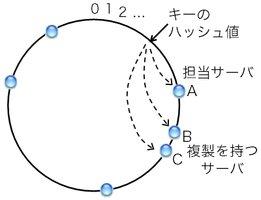
図6: consistent hashingでの複製の持たせ方の例(時計回り方式の場合)
複製を作るためには、どのサーバに持たせるかを决める必要がある。 以下、筆者がOverlay Weaver(コラム参照)に実装した方式を紹介する。 図2を使って説明したリング状ID空間、時計回りのconsistent hashingを想定する。 図6の通り、あるキーを担当するサーバがAであったとする。 仮にサーバAを除去したら、時計回りに、Bが担当サーバとなる。 Bも除去したらCが担当サーバとなる。 この、担当サーバとして適切な順、つまりサーバA、B、Cという順に、 このキーと値を持たせる。 こうしておくことで、もしAが故障して反応しなくなったら、 自然にBが担当サーバとなりBからデータを得られる。 Bも故障した場合も同様である。 また、サーバの除去によって複製が減っていくことへの対策として、 サーバ間で自動的に複製を作ったり、 新たに追加されたサーバは自身が持つべき複製を勝手に取得したり、 といった手法も実装してある。
このように複製を作成する場合、サーバの追加・除去があると、 データの格納、上書き、削除、取得のタイミングによっては、 サーバごとに保持しているデータが食い違うということが起き得る。 もちろん、関係するサーバ間で2フェーズコミットで トランザクション処理を行うという手もあるにはある。 しかし、この種のそれなりの台数を想定したシステムでは、 ロックに起因するブロックやタイムアウト待ちが嫌われてか、あまり採用されない。 代わりに、一時的、過渡的な不整合は許容し、 不整合の解決はデータベースを使う側に任せるという方針が採られることが多い。 これはつまり、一貫性を重視する ACID(Atomicity, Consistency, Isolation, Durability) の代わりに BASE(basically available, soft state, eventually consistent) で得られるスケーラビリティを重視するという設計思想である。
データベースを稼働させたままで、サービスを止めることなく サーバを追加したい、除去したいというのはよくある要求であり、時に必要である。 そうでなくとも、台数が増えるに従って故障は日常茶飯事となるので、 一部分で故障があっても全体は止まらないこと(partial failureの許容)が 重要となる。
サーバの除去は、クライアント、中継サーバ、他のサーバへの通知なしでも何とかなる。 除去されたサーバはアクセスに対して返答しないので、 その時点でサーバ一覧表から消すなり、消さずとも他の適切なサーバに アクセスすればよい。 もっとも、除去されたサーバが担当していたデータについては、 他サーバへの事前の複製なり除去前の委譲なりがあって初めて、 除去後もデータを取得できる、ということは言うまでもない。
何とかなるとはいえ、除去や故障によって存在しなくなったということを ネットワーク越しに判断するには、 必ず、ある程度の時間待ってみる必要があるので、 その待ち時間の分、アクセスの処理が遅れることにはなる。 例えば、通信プロトコルTCPでは、 インターネット上でパケットが失われたと判断して再度送信するまでの待ち時間を RTT(通信の往復時間)に基づいて决める。 分散データベースの場合も、 例えばRTTが0.1秒であれば少なくとも0.1秒は待ってみないと サーバの生死は判断できないので、その分、処理が遅れることになる。 こういったアクセス時の遅れを防ぐために、 アクセスする側からサーバの除去をあらかじめ検知しておくという方法もある。 しかし、そういった通知や検知のためには普段からの通信が必要となるので、 どちらが良いかは場合による。
一方、サーバの追加は、何らかの方法でクライアント、中継サーバ、他のサーバといった サーバ一覧表を持つコンピュータに知ってもらわないわけにはいかない。 一覧表に載っていないサーバには当然アクセスが行かないので、 サーバ追加のそもそもの意味がなくなってしまう。
一覧表を持つ全コンピュータに把握させる方法には、様々なものがある。 特に台数が多い場合の手法は、まだまだ研究が行われている。 単に追加されたサーバ自身や管理サーバから通知する方法、 一覧表を持つコンピュータの側からサーバの生死を確認・検知する方法、 また、検知した結果を他に通知するという組み合わせ手法などなど、様々である。 通知の方法にしても、単に1台から全通知先に逐一通知する方法、 通知を中継していく方法 など、様々なものがある。 中継するにしても、台数が多いと通信回数が増え時間もかかるので、 1台が2台に、2台が4台にというように樹状に中継していく方法、 また、そのための木構造をうまく構築する方法などなど、関連技術は尽きない。
そもそも図5 (1)、(2)の構造そのままでは、サーバの追加・除去を サーバ一覧表を持つ全コンピュータ(全クライアント、全中継サーバ)に 知らせる方法がない。 サーバ一覧表を持つ全コンピュータを、どのコンピュータも把握していないからである。 通知対象の数が少なければ手で設定してもよいが、 多い場合には何かしら追加の工夫が要る。
どんな方法で知らせるにせよ、 各コンピュータが持つサーバ一覧表の内容に食い違いがあると、 アクセス元によってデータを得られたり得られなかったりという不整合が起こる。 これを完全に防ぐには、 サーバ一覧表を1つだけにしてしまう (全クライアントから単一の中継サーバを使う)か、 すべてのサーバ一覧表の間で一貫性を保つ必要がある。 どちらにせよ、性能上極めて不利であるか、現実的ではない。 この点、完全な一貫性よりは条件を緩めて、 一時的、過渡的な不整合は許容するという方針、 つまりACIDの代わりにBASEに従わざるを得ない。
割安なPCやサーバが塔載するメモリやディスクの容量は限界があり、 1台あたりのアクセス性能も、 今日では数万〜数十万クエリ/秒というあたりに限界がある。 その1桁、2桁上の容量やアクセス性能が必要な場合、 どうしても数十台、数百台のサーバを並べる必要が生じる。
上で述べた図5 (1)〜(3)の構成、そのいずれにせよ、 全サーバを把握しているコンピュータがあるという前提を置いている。 (1)であればクライアント、(2)であれば中継サーバ、 (3)であれば全サーバが、全サーバの情報が載ったサーバ一覧表を持つ。 前述の通り、BASEに従って若干の遅れは許容するにしても、 各コンピュータが持つサーバ一覧表は 最新かつなるべく一貫した状態に保たねばならない。 これは、サーバの台数が増えるに従って困難さが増してくる。 例えば、(1)や(2)の構成でサーバが100台あるとする。 サーバに対する生存確認は、 サーバ一覧表を持つコンピュータのうち2台が代表して行うとする。 生存確認を行う度に、問い合わせと返答合わせて400のメッセージが飛ぶので、 5秒に1回生存確認を行うとすると、1秒あたり平均80メッセージが飛び交うことになる。 (3)の構成では、サーバ一覧表を持つ全サーバから全サーバに対して生存確認を行うと、 メッセージ数が大変なことになる(100台で19800メッセージ)ので、ひと工夫が要る。 例えば、生存確認を各サーバで分担して、 追加・除去を検知したら他のサーバに通知すればよい。 しかし、どの構成でどういう工夫をするにせよ、 秒あたりのメッセージ数は最低でもサーバの台数に比例する。 それを送受信するコンピュータ、ネットワークの負荷を考えないわけにはいかない。
こういった方法は果たして何台まで通用するだろうか? サーバ100台で80メッセージ/秒はもしかしたら許容されるかもしれないが、 生存確認のためだけに1,000台で800、10,000台で8,000メッセージ/秒はどうだろうか。
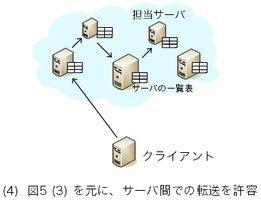
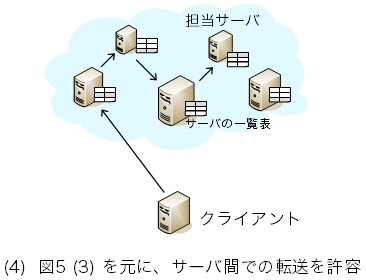
図7: 転送を許す構成 --- 分散ハッシュ表(DHT)・構造化オーバレイ
分散したサーバ一覧表の間で一貫性を保とうとするから大変になるのである。 ここで、一貫性の条件を緩める方法がある。 問い合わせのサーバ間での転送を許すのである(図7)。 つまり、データ格納・取得等の問い合わせを受けたサーバが 担当サーバを直接は知らなかった場合、 他の、より適切と思われるサーバに問い合わせを回すのである。 問い合わせ自体を転送してもよいし、 より適切なサーバを問い合わせ元に知らせてもよい。 peer-to-peerの用語で、前者の転送方式をrecursive lookup、 後者をiterative lookupと言う。 こういった転送は、サーバ自身がサーバ一覧表を持つことを前提とするので、 図5で言うと(1)、(2)ではなく(3)のシステム構成が前提となる。
転送を許すことで、必ずしもサーバ一覧表が完璧である必要はなくなる。 言い換えると、全サーバが全サーバを知っている必要がなくなる。 これによって、サーバ一覧表の維持管理がずいぶんと楽になる。 つまり、維持管理に必要なメッセージ数を大幅に減らせる。 また、一覧表のサイズもかなり小さくでき、 一般的に、サーバ数Nの場合にO(log N)となる。 これは、Nが10、100、1000…と増えても 表のサイズは10、20、30という増え方しかしないという性質であり、 スケーラブルなシステムに大切な性質である。 同様に、転送の回数も多くの方式でO(log N)となる。
ただし、転送の末にキーの担当サーバまで到達できることは保証されていないと困る。 それを(少なくともサーバの追加・除去のない状況では)保証するアルゴリズムが、 実は、peer-to-peer由来の分散ハッシュ表(DHT)である。 ルーティング技術というもう少し広い観点では 構造化オーバレイネットワーク(以下、オーバレイ)と呼ばれる。
そう、転送を繰り返して目的地に到達するということは、ルーティングなのである。 ここまで遣ってきた用語をルーティングの用語で言い換えると、次の表の語となる。
ルーティング用語 サーバ一覧表 経路表 一覧表の維持管理 ルーティング 転送 フォワーディング
ルーティングの方式、つまり、DHT、構造化オーバレイの方式にも 様々なものがある。 2001年にCAN、Chord、Pastry、Tapestryが提案されて以来、 数多くのアルゴリズムが提案されてきた。 また、BitTorrentプロトコルを実装しているファイル配信ソフトウェアのうち 20を超えるものがKademliaというDHTの一方式を実装しており、 それによって、トラッカというある種のサーバなしでの動作を可能としている。
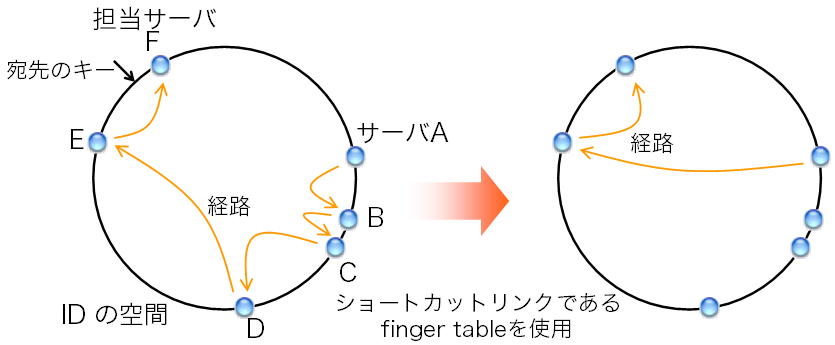
ここで、DHT、構造化オーバレイの一方式であるChordを説明する。 Chordは、図2で説明した時計回りのconsistent hashingに基づく。 まず、各サーバは時計回りで次にあたるサーバ(successor)へのリンクを持つ。 つまり、IDを把握して、IPアドレスを把握するなりTCP接続を張るなりする。
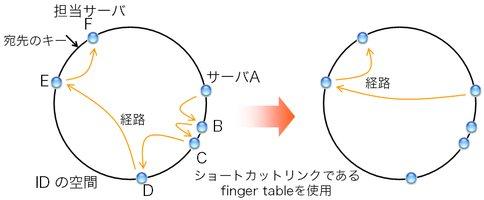
図8: Chordでの経路
図8の状況を考えよう。 サーバAからあるキーの担当サーバFに辿り着きたいとする。 サーバAは、自身のIDとsuccessorであるBのIDを見て、 Bが担当サーバでないと判断する。 Bの担当範囲はサーバAのID+1からサーバBのIDまでなので、 AとBのIDを基に判断できるのである。 担当サーバでないことを申し添えて、問い合わせをBに転送する。 同様に、Eまで転送が繰り返される。 Eは、自身とsuccessorであるFのIDから、Fが担当サーバであることを知る。 そしてFに問い合わせを転送する。 これで晴れて担当サーバFに問い合わせが到達した。
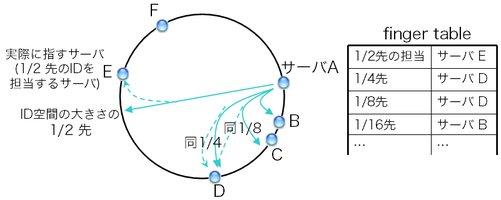
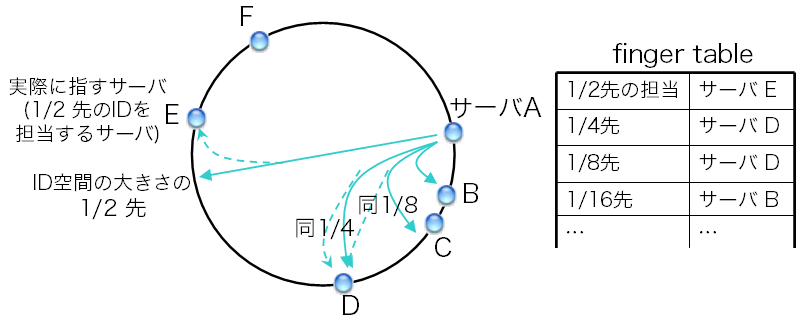
図9: ショートカットリンクであるfinger table
図8左図の通り、担当サーバに到達するまで5回の転送が行われた。 この方式の残念な点は、転送の回数がかさむことである。 台数に比例した回数の転送、つまりO(N)の転送が必要となる。 例えば、サーバが100台ある状況では平均して50回の転送が必要となる計算である。 これでは困るので、ショートカットのためのリンクを用意する。 図9の通り、自身を起点として、 ID空間の大きさ(例: 2160)の1/2だけ進んだ先のIDを担当するサーバ、 1/4先のIDを担当するサーバ、1/8の担当サーバ…へのリンクを用意する。 このリンクの表をfinger tableと言う。 Chordの経路表は、最低限、successorとfinger tableから成る。
finger tableを参照することで、 先ほどの手順のようにsuccessorを一歩一歩辿るのではなく、 ひと足飛びに担当サーバに近付くことができる。 先ほどの例では、サーバAは宛先キーとfinger tableを見ることで、 ひと足とびにサーバEまで飛ばしてよいことが判る。 これによって、先ほどの手順では5回の転送が必要だったところ(図8左)、 2回の転送で担当サーバに到達できる(図8右)。 これで転送の回数がO(N)からO(log N)に減った。 1台あたりの経路表のサイズもO(log N)に抑えられている。 ID空間の大きさが2160の場合、 どんなにサーバ数が増えてもfinger tableが持つエントリ数はたかだか160である。
ここまでで、転送先(next hop)を决める手順を説明した。 DHT、構造化オーバレイを動かすためには、他にも次の手順が必要となるが、 ここでは割愛する。
分散したサーバ一覧表の間で一貫性を保つことは、 表を持つコンピュータの数やサーバの数が増えるに従って困難になってくる。 その一貫性の条件を緩めるために、サーバ間での転送、構造化オーバレイという手法が あることを説明した。 しかし、転送するということは、転送の時間がかさむということである。 そのコストの元をとれるだろうか?
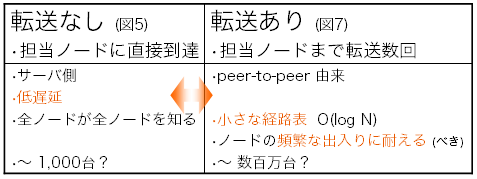
図10: 「転送なし」「転送あり」それぞれの利点
以下では、全サーバの一覧表がある構成(図5)を「転送なし」と呼び、 サーバ間の転送を許す構造化オーバレイ(図7)を「転送あり」と呼ぶ。 両者の性質と利点を図10にまとめた。
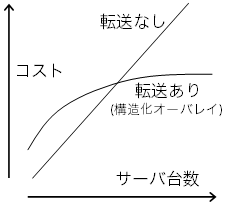
図11: サーバ台数に従って増えるコスト間のトレードオフ
それぞれ、サーバの台数に応じた次のコストがかかる。
では、転送あり方式の元をとれるのは、その間の何台あたりであろうか。 これは、場合によるとしか言えない。 これらのコストは、もちろん、 オーダー(O(…))だけで論じられるものではない。 実装の仕方によって大きく変わってくるというだけでなく、 コストがかかるタイミングも、サーバ追加・除去時とアクセス時、といったように それぞれ異なり、それも踏まえて検討する必要がある。 現実のソフトウェア実装を考えると、転送ありの方がどうしても複雑になるので、 それを安定動作させるまでの労力と時間も考えに入れざるを得ない。
ここまで、担当サーバへ直接到達する「転送なし」と、 「転送あり」の構造化オーバレイ、DHTを対比させ、比較してきた。 今日まで、技術者は両者を別物として扱い、 研究者は「転送なし」を構造化オーバレイ、DHTには含めずに考えてきた。

図12: 「転送なし」の構造化オーバレイとしての位置付け
しかし実のところ、「転送なし」は、 構造化オーバレイの特殊形と位置付けることが自然である。 一般的な構造化オーバレイは、サーバ台数Nとすると、 経路表サイズO(log N)、経路長(転送回数)O(log N)である。 そこに「転送なし」を位置付けると、 経路表サイズO(N)、つまりサーバ台数に比例、 経路長1、つまり転送なし、となる(図12)。
実際に、構造化オーバレイの方式を元に、 経路表のサイズを大きくしていくと、それは「転送なし」になっていく。 具体的な方法としては、Chordにおいてsuccessor listの長さを無制限とする、 Pastryにおいてleaf setの大きさを無制限とする、といった方法が考えられる。 もっとも、サーバ情報をサーバ間できちんと流布させる仕掛けを 追加する必要はあるかもしれない。 このことはまた、構造化オーバレイの方式を元にして、 「転送なし」への近さ、つまり経路表サイズと経路長のトレードオフを 細かく調整できるという可能性を示唆している。
「転送あり」ではデータベースへのアクセス時に転送コストがかかり、 サーバ何台でその元をとれるのかは場合による、と説明した。 構造化オーバレイを理解し、 自分達のやろうとしていることでなら元がとれると判断した者、 もしくは、「転送なし」のスケーラビリティ限界に縛られるリスクを避けたい者が 構造化オーバレイを使うだろう。 最近、Microsoft社がその一社となった。
Microsoft社は、2008年10月、クラウドプラットフォーム Windows Azure Platform(以下、Azure)を発表した。 Azureは次のように構造化オーバレイを使っている。
Azureが用いる構造化オーバレイの方式は、 さしづめ、両方向版Chordとでも呼ぶべきものである。 本稿で説明した通り、Chordは時計回りのconsistent hashing(図2,3)を前提とする。 一方、Azureの両方向Chordは、 最近値方式のconsistent hashing(図4)を前提とする。 そのため、リング状ID空間の上で担当サーバに近付いて行く際、 時計回りに限らず、両方向どちらでも、距離が近い方向を選んで近付いて行く。 そのため、finger tableも両方向に持つ。
マサチューセッツ工科大学からChordが発表された2001年、 Microsoft社の研究部門Microsoft Researchの研究者がPastryという方式を発表した。 このPastryは最近値方式のconsistent hashing(図4)を前提とする。 Azureの設計にPastry関係者が関わったかどうかは知らないが、 Microsoft社がAzureの基礎にPastryではなくChordを選び、 しかしChord流の時計回り方式ではなくPastry流の最近値方式を選んだというのは 大変興味深い。
本稿では、分散データベースのscale out手法を説明した。 データ分割から始めて、 scale outを可能にする担当サーバ决め手法consistent hashing、 また、サーバ一覧表の一貫性という重荷を脱ぎ捨ててさらなる スケーラビリティを手に入れるための技術、構造化オーバレイを説明した。
2007年2月、Google社が、国内では珍しく、 Googleが提供するサービスの「使い方」ではなく、中身の「作り」がどうなっているか という技術講演会を開催してくれた。 Gmail開発者の講演に加えて、 表形式の分散DBであるBigTableの内部についての講演があった。 にもかかわらず、そこで聴衆から出た質問は、 mash upして作ったサービスの権利は? サービスを提供し続けるという表明をすべきでは? といった「使う」側での質問ばかりであった。
たしかに、クラウドを「作る」という機会など そうそう降ってくるものでもないので、 多くのエンジニアは我が身のことと感じられないのかもしれない。 しかしその裏で、 スケーラブルなkey-valueストアといった クラウドの基本ソフトに取り組んでいるエンジニアも、 日本国内だけで二桁以上いるのである(コラム参照)。 彼らがそれをクラウドと呼ぶかどうかはともかく、である。 本稿を読んだ方に、作る、作れる、という気持ちを持って頂けたとしたら、 望外の喜びである。
また、クラウドをうまく使うためには、 その構造を知っておくに越したことはない。 例えば、Azureの表は、 分割キーの条件を問い合わせに含めるか否かで処理効率が大きく違ってくる。 より大局的には、BASEで充分な応用、個所、つまり使いどころを見極める目や、 非同期のメッセージング等によって ACIDを保たねばならない範囲(データ領域や台数)を 小さく保つ技術が重要となるだろう。
key-valueストアという名前には、 キーと値の組(key-value pair)を格納するデータ格納ソフトウェア というくらいの意味しかない。 格納した値はキーを与えることで取得できる。 広義には、例えばJava言語のjava.util.Map型オブジェクト、 Python言語のマップ型(mapping)オブジェクト等、 たいていのプログラミング言語が持っているマップやハッシュ表も含まれる。
ライブラリとして利用するものとネットワーク越しにアクセスして利用するものがある。 前者には、古くはBerkeley DB、 最近では平林氏のTokyo Cabinetや山田氏のLux IO等がある。
ネットワーク越しにアクセスするkey-vlaueストアには、 1台で動作するものと、複数台にデータを分散させられるものがある。 1台で動作するものとしては、最近、memcachedが非常に広く使われており、 Facebook、YouTube、Twitter、Digg、はてな、mixi等のウェブ上サービスの裏側で 使われてきた実績がある。 mixiでは100台以上での動作実績があり、 Facebookでは1,000台近くでメモリ容量の合計28テラバイトという実績がある。 1台での動作とはいえ、アクセスする側のクライアント側ライブラリが キーごとに担当サーバを决めることで、 複数台にデータを分散して格納することができる。 ライブラリの種類によっては、 consistent hashingを用いてキーごとの担当サーバを决めることができる。
複数台にデータを分散させられるソフトウェアの数も多い。 Amazonの内部で使われているというDynamoは、2007年に論文が発表され、 多くのエンジニアに影響を与えた。 企業の製品としては、IBM社のObjectGrid、Oracle社のCoherence等がある。 どちらもJava言語のオブジェクトをメモリ上に保持するkey-valueストアである。 典型的には、リレーショナルDBから得たデータのキャッシュや、 HTTPセッション情報といった有効期間が短いデータの保持に使われている。 また、日本のエンジニアが開発しているものだけでも、 上野氏のCagra、GREEのFlare、たけまる氏のKai、古橋氏のkumofs、 楽天技術研究所のROMAと、かなりの数がある。 これらとは若干趣きは違うが、 筆者はpeer-to-peer由来の技術である分散ハッシュ表(DHT)を用いた key-valueストアOverlay Weaverを開発している。 35ヶ国500台以上の実機で運用している他、 1台上では最大15万ノードでの実験を行っている。
複数台を連携させる方式としては、ソフトウェアによって、 全体を管理するサーバがあるもの、 データを持つサーバ間でデータをやりとりするもの(一部peer-to-peer)、 また、管理サーバがなく完全にpeer-to-peerであるものがある。
多くのサーバ、例えば数十台以上にデータを分散させることを狙うソフトウェアには、 キーごとの担当サーバ决めにconsistent hashingを用いるものが多い。 Dynamoもそうであり、DynamoのErlang言語での実装として始まったKaiの他、 Cagra、kumofs、ROMAもconsistent hashingを用いる。 peer-to-peer由来の分散ハッシュ表もたいていconsistent hashingに基づく。
ネットワーク越しにkey-valueストアを利用するための通信プロトコルとしては、 memcachedプロトコルを実装しているものが多い。 これは、memcachedが広く使われているためである。 memcachedプロトコルを実装しておけば、 memcachedが使われている状況で置き換えて動作させることが可能となる。
ネットワーク越しに利用するkey-valueストアには、 データをメモリ上のみに置くものと、 ディスク等の二次記憶装置に記録するものがある。 また、切り替えられるように作られているソフトウェアも多い。 例えば、読み書き性能を追及する場合はメモリを使用、 それ以上の容量や永続性が必要な場合は二次記憶装置を使用すればよい。
どちらの開発を優先させているかは、ソフトウェアごとの方針による。 具体的には、memcachedはメモリ上での記憶を前提とし、 Dynamoは切り替えが可能ながら、 実際の運用ではBerkeley DBを用いて二次記憶装置に記録することが多い(論文より)。
本文で述べる通り、リレーショナルDB(RDB)では、 ある程度の台数にデータを分散させようとすると、 行ごとに各サーバに分散させることになる。 この際、特定の列を分割キー(partition key)として指定する必要がある。 こうして構成した分散RDBに問い合わせを行う場合、 分割キーについての条件を指定しないと全サーバへの問い合わせが起きてしまう。 よって、分割キーについての条件を指定することが望ましい使い方、 ということになる。
もう一歩進めて、問い合わせの際には 「分割キーの値は必ず指定する」(制約1) ということに决めたとしよう。 こうなるともう、それはkey-valueストアと変わらない。 key-valueストアに対して、 表の分割キーをキーとして、また、他の列の内容全体を値として格納すれば、 制約1を付けたRDBと同じだけのことができる。 つまり、key-valueストアを使って制約1付きのRDBを実装することができる。
制約1はそれなりに厳しいものなので、 RDBの機能のうち使えなくなるものは出てくる。 制約1なし、つまり、分割キーの値を指定しない問い合わせでは、 全サーバの、場合によっては全データを調べる必要が生じる。 純粋なkey-valueストアは、そういったサーバをまたいだ処理を行う機能を持たない。 一方、分散RDBはそれをなんとか処理する機能を持つ。 それだけの違いである。 key-valueストアにその機能を足せば、分散RDBとなる。
以降、水平分割の分散RDBはkey-valueストアのようなものである、と考えてみる。 実際、RDBは、単なるkey-valueストアのように使われている場合も多い。 すると、key-valueの値の内容、 つまり各行が持つべきデータの形式をきっちりと事前に定義したり、 DB全体に渡って統一する必要がなぜあるのか? つまり、DB全体に渡るスキーマを定義する必要があるのか? という疑問が湧くだろう。 key-valueストア自体には、値の内容についての制約は何もないので、 各行の内容は何でもよく、統一されている必要もない。
従来RDBのデータモデルでは、 あまねくすべての列でjoin等の演算ができることが必要とされてきた。 しかし分散DBでは分割キーを指定しない処理は効率が悪く、性能が出ない。 どうせ性能が出ないのなら、分割キー以外の列は必須としなくてもよいのではないか。
また、こういった分散DBからの要請だけでなく、 厳格に構造(スキーマ)を定義することが困難であったり、 しない方が便利であったりする応用向けに、 半構造データ(semi-structured data)を扱う技術やDBMSが台頭している。 代表的な対象データは、ウェブコンテンツやビジネス文書等である。
こういった事情から、スキーマを必要としないDBMSが数多く現れてきている。 現に、Microsoft社のクラウドプラットフォームWindows Azure Platformの Windows Azure Storageでは、表全体に共通するスキーマというものがない。 Apache CouchDBもスキーマのないDBMSである。 キー(_id)で半構造データを検索できる。