図1 アプリケーション層マルチキャスト
首藤一幸, "アプリケーション層マルチキャスト:基本と応用", UNIX magazine 2006年 10月号, pp.34-43, (株)アスキー, 2006年 9月 16日
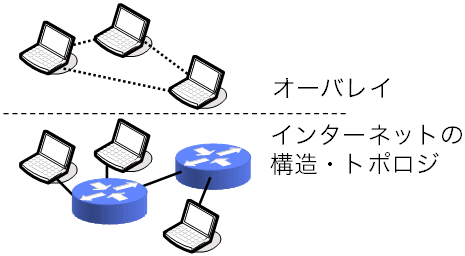
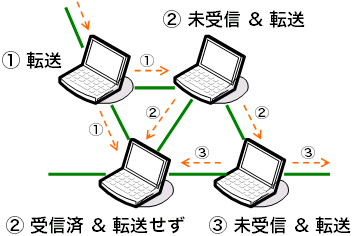
IPマルチキャストは、その提案から十数年を経た今でも、 インターネットの津々浦々で使えるという状況には至っていません。 そこで、インターネット自体ではなく、 その上で動作するアプリケーションにマルチキャストをさせようという研究が 2000年前後から盛んに行われています。 このようなマルチキャスト手法は、 アプリケーション層マルチキャスト (application-levelまたはlayer multicast, ALM)と呼ばれます (図1)。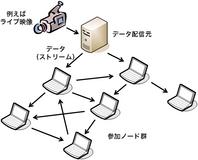
図1 アプリケーション層マルチキャスト
ALMでは、ALMに参加するコンピュータ、すなわちノード群が、 インターネットのそれとは異なる構造・トポロジを構成します (図2)。 こういったアプリケーション層のネットワークは、ALMに限らず、 オーバレイネットワーク、ネットワークオーバレイ、または単に オーバレイと呼ばれます。 ALMは、オーバレイ上で行われるマルチキャストという観点から、 オーバレイマルチキャスト(overlay multicast) とも呼ばれます。 ALMには他にもエンドシステムマルチキャスト(end-system multicast)、 エンドホストマルチキャスト(end-host multicast)という呼び名もあります。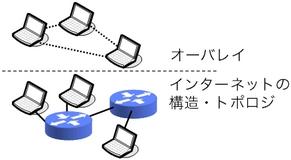
図2 オーバレイ
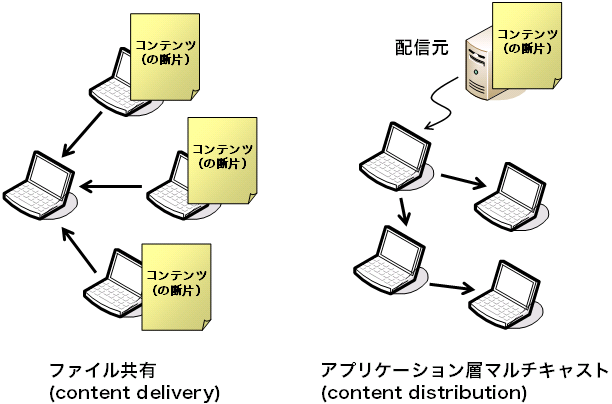
P2Pシステムと言って最も有名なのは、 GnutellaやeMule、Winny、BitTorrent等に代表される ファイル共有ソフトウェアでしょうか。 ファイル共有ソフトの主なコンテンツは今のところ動画像や楽曲であり、 ALMのそれと重なります。 しかし、ALMとファイル共有ソフトとでは技術的な要件がかなり異なり、 難しい点も異なります。
根本的な違いは、事前にコンテンツをバラまいておくことができるのか否か、です (図3)。 ファイル共有ソフトは一般に、 コンテンツ、またはその断片を複数のノードに複製しておきます。 これによって、コンテンツ片の入手可能性を高め、 コンテンツ供給元へのアクセス集中を防ぐわけです。 複製をどのノードにどのくらいの数用意すればよいかを決めることは P2Pでなくとも容易ではなく、 これだけでひとつの研究領域を成しているくらいです。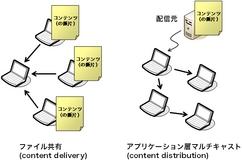
図3 ファイル共有とALM
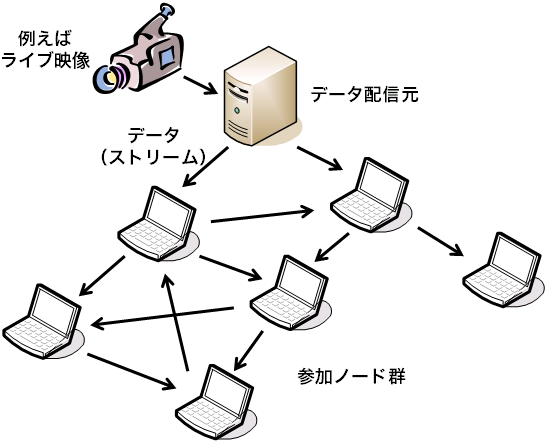
一方ALMでは、事前にコンテンツをバラまいておくことはできません。 ある瞬間には1台のコンピュータ、データ配信元にしか存在しないデータを、 ごく短い時間の間に多数のノードに配布しなければなりません。 一般的には、数十ミリ秒から1分程度の間に、数十台から数十万台以上に対して 配布することが求められます。 ALMの難しさは、この点、つまり、安定的に使えるわけではない、 いつ電源を切られるかわからないコンピュータを使って、 限られた時間で多数のノードに対していかにデータを配布するかという点にあります。
とはいえ、すべての点においてALMの方が難しいというわけではなく、 両者にはそれぞれの難しさがあります。 例えば、ファイル共有ではコンテンツ片を二次記憶装置、 一般的にはハードディスクに複製・キャッシュ するので、ディスクの領域管理を行う必要があります。 ディスクの容量は無限ではありませんし、 ファイル共有のためにディスクの全領域を使うわけにもいきません。 ディスク・メモリ上のコンテンツ片について、 どれを保持してどれを削除するのかという判断が要ります。 一方でALMでは、各ノードは、隣接関係にあるノードに対して 渡してしまったデータを保持し続ける必要がありません。 このように、データの取捨選択は一般的にALMの方が容易です。
ピュアP2P(⇔ハイブリッドP2P)を想定すると、 ファイル共有の側には、利用者が求めるコンテンツを いかに効率よく探索・発見するかという難しさがあるように思われます。 この、探索・発見という課題に対して、 非構造化オーバレイではflooding、random walk、bloom filter 等の効率向上の試みがあり、構造化オーバレイでは 持ち味である効率の良さに加えて探索の柔軟性を両立させようという 研究が進められているわけです。 しかし本質的には、ALMにもコンテンツの探索・発見という問題は伴います。 ファイル共有では、探索・発見の手法が、 発見が済んだ後に行われるコンテンツ供給の手法よりも注目を集めており、 ALMでは逆にコンテンツ供給の方がその難しさから注目を集めている というだけに過ぎません。 ALMでもファイル共有のように多くのコンテンツが扱われるとすれば、 ファイル共有と同様に探索・発見手法が重要になります。
と言っても、それらすべてがまったく異なる手法を採っているわけではなく、 いくつかの観点から手法を分類することができます。 主な観点は次の通りです。
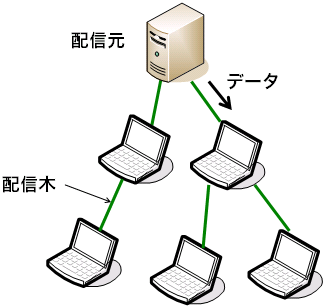
ツリーベース(tree-based)の手法では、 ノード群がマルチキャストのためのデータ配信木(distribution tree)を構築し、 木構造に沿って根から葉に向かってデータを転送します (図4)。 マルチキャストと聞いて最初に思い付く、最も素直な方法ではないでしょうか。 データがオーバレイを流れる前に流路(配信木)が定まっているため、 データがあるノードに到達するまでの時間、すなわち遅延と、 遅延の揺らぎ、すなわちジッタを低く抑えやすいという利点があります。 また、配信木の形状がすなわちデータの流路なので、 配信木の構築を通してデータの流路を厳密に制御できるという利点もあります。 帯域幅の狭い経路、不安定な経路を明示的に避けるといったことも素直に行えます。 一方で、ノードの故障や、日常的に起こる突然の離脱に際しては、 素早く配信木を修復しなければならず、 ここで問題が生じると配信の失敗が生じます。 故障、離脱したノードが配信木の根に近かった場合、 その影響は大きいものとなります。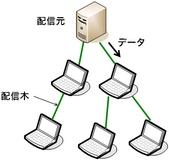
図4 ツリーベース (tree-based) の方式
ツリーベースの手法でまず問題となるのは、配信木を構築する方法です。 マルチキャスト用のオーバレイにノードが直接いきなり参加する方法もあれば、 事前にノード群でメッシュ(=グラフ)を構成しておいて その上に配信木を構築する方法もあります。 前者にはOvercastやYoidが、後者にはNaradaやALMIが該当します。 例えばNaradaは、IPマルチキャストの配信木構築プロトコルである DVMRPと同様の手法で配信木を構築します。
木構造の構築に構造化オーバレイ(structured overlay)を用いる方法もあります。 構造化オーバレイとは、 ノード間の隣接関係にアルゴリズム上の制約が設けてあるオーバレイを指します。 その上で、ノードとオブジェクト(ファイル等)の双方に振られたIDの値に基づいて ルーティングが行われます。 構造化オーバレイの応用として最も有名なのは 分散ハッシュ表(Distributed Hashtable, DHT)でしょう。 他にも、メッセージ配送や、これから述べるように マルチキャストやエニーキャストへの応用が可能です。 構造化オーバレイのアルゴリズムは2001年から多数の発表があり、 代表的なものにChord、CAN、Pastry、Tapestry、Kademliaがあります。
構造化オーバレイでは、各ノードにIDが振られます。 IDは160bitや128bitの非負整数であることが多く、 SHA1などの暗号学的ハッシュ関数の出力が使われることも多いです。 各ノードはID空間(リング)の一部分、一般的には自らのIDの周辺を担当します。 ここで例えばDHTであれば、各ノードは、キーの値が自らの担当である場合に、 そのキーと値の組を保持します。 そして検索の段階では、キーの値を宛先としたルーティングが行われます。 このルーティングは該当するキーと値の組を保持しているノードに到達する、 というわけです。
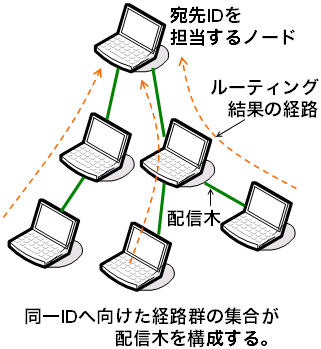
ここで、同一のIDを宛先として、複数の異なるノードから ルーティングを行った場合を考えます。 各ルーティングそれぞれの経路は、最終的には同一の担当ノードに収束します。 これら複数の経路の和集合は木構造を構成します(図5)。 この木構造を配信木として使おうというのが、 構造化オーバレイを使ったマルチキャストの基本的なアイディアです。 Scribeは、構造化オーバレイのアルゴリズムであるPastryを使って配信木を構築し、 配信木の根をrendezvous point(RP)として そこから葉に向けてデータを転送していくというALMです。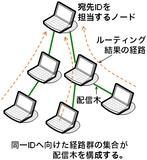
図5 構造化オーバレイを使った配信木の構築
ここで、配信木を構成する各ノードの上り帯域幅について考えます。 子を持つノードは、データを子に転送するために上り帯域幅を活用しています。 持ち得る子の数が上り帯域幅によって制限される点にも注意してください。 このことは、配信木を構成する際に、各ノードの帯域幅、 特に上り帯域幅を考慮する必要があることを意味します。 続いて、子を持たないノード、つまり配信木の葉の場合はどうでしょう。 他のノードに対してデータを転送していないということは、 上り帯域幅を活用していないことになります。 木構造において葉となるノードの数は案外多いものです。 各ノードが2つの子を持つバイナリツリーですら、 半分強のノードが葉となります。 各ノードが16の子を持つとしたら、9割を越える数のノードが葉となります。 ALMにおいて系全体にとっての貴重な資源である上り帯域幅を活用しないというのは もったいないことです。
そこで、複数の配信木を構築して、 それぞれの配信木ではデータの一部分を流すという手法が考えられました。 SplitStreamは複数の配信木を構築するALMです。 ここで構築される複数の配信木はforestと呼ばれます。 それぞれの配信木はScribeの手法で構築し、 データストリームを時間方向に分割したものを複数の配信木に分散して流します。 つまり、ノードは必要なデータを揃えるために、 複数の配信木に参加することになります。 各ノードはどれかただひとつの配信木で子を持ちます。 複数配信木を構築するALMには、他にChunkyspreadなどがあります。
これに対して、より緩やかなノード間の関係に基づいてデータを転送していく メッシュベース(mesh-based)の方式も提案されています。 ここでは、ノード間に親子といった定まった方向がなかったり、 さらには、ノード間の関係が枝の有無といったゼロ/イチでは定まらないような、 比較的ノード間の関係が緩やかな構造をおおざっぱにメッシュと呼びます。
メッシュ上で全ノードに対してデータを配布する方式として、 floodingという単純な方式がよく知られています (図6)。 floodingは日本語で言うと「洪水」「氾濫」であり、文字通り、 メッシュ上にデータを氾濫させます。 P2P関係では、ファイル共有プロトコルGnutellaで 検索クエリの拡散にfloodingが使われていることが有名です。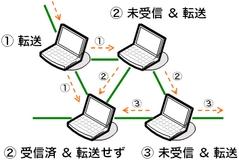
図6 flooding
floodingでは、各ノードは隣接ノードに対して強制的にデータを送りつけます。 つまりpush型の方式です。 データを受信したノードは、そのデータの受信が初めてであれば、 データが来た方向を除いて、自分の隣接ノードに対してデータを転送します。 受信済であれば転送しません。
単純なfloodingには、データ転送の総量、それも無駄なデータ転送が多いという 問題があります。 例えば図6中のあるノードは、同一のデータを4回以上受信しています。 各ノードの上り帯域幅が貴重な資源であるALMにおいて、これは大きな問題です。 そこで、ALMにfloodingを適用する場合には、 必ずと言っていいほど、無駄なデータ転送を低減する工夫が採り入れられています。
floodingの良い点、つまり高いデータ浸透率を維持しつつ、 なおかつデータ転送の総量を抑える手法として、 1980年代にgossipと呼ばれる手法が考え出されました。 gossipはrumor mongering、epidemic disseminationとも呼ばれます。 文字通り、噂が人づてに伝わっていく様に似た動作をします。 gossipプロトコルには多くのバリエーションがあります。 基本的には、転送処理としては、 隣接ノードの中から転送先をランダムに選び転送する、という動作を繰り返します。 ここで例えば、受信済ノードへの転送を一定回数繰り返してしまった時点で、 転送を止めます。
この種のプロトコルのALMへの応用としては、 構造化オーバレイCANの上でfloodingを行うものがあります。 floodingはALM自体よりも、 イベント通知(例:lpbcast)や オーバレイのメンバ管理(例:CoolStreaming/DONet)によく用いられています。
BulletというALMは、ノード間の木構造を前提としながらも メッシュベースの手法を採っています。 最初は配信木に従ってデータを流しますが、 各ノードはすべての子に全データを流すわけではありません。 各ノードは、足りないデータは、木構造に関係なく他のノードから入手します。 この点がメッシュベースである所以です。 どのノードがどのデータを保持しているかという情報は、 木構造を活用して流通させます。 この手法によってツリーベースよりも 高帯域幅のデータを流すことができる、というのが提案者の主張です。
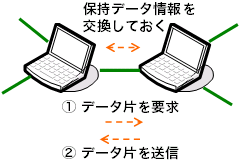
かといって、隣接ノードに対して闇雲にデータを要求しても、 その隣接ノードが当該データを持っていなければ、 要求自体が無駄なものとしかなりません。 そこで、自らが保持しているデータの一覧を隣接ノードに知らせておく という方法が採られます。 具体的には、データストリームを時間方向に分割したものにシーケンス番号を振り、 その番号やビットマップで保持データを表現し、隣接ノードに通知しておきます。 これによって各ノードは隣接ノードがどのデータ片を保持しているかを 知ることができ、これに基づいて、データ片を要求できます。
この方法はデータ駆動(data-driven、data-centric)と 呼ばれます(図7)。 良い点は、 ツリーベースでは欠かせないノード故障・離脱時の木構造の再構成が不要であること、 メッシュベースのpush型プロトコルで起こりがちな無駄なデータ転送をなくせること です。 前者を理由として、 ノードの頻繁な出入り(churn)に強い(resilient)という生来の性質を持ちます。 ただしこれは、隣接ノードの選択・管理アルゴリズム、 つまり、どのノードをどういった基準に基づいて隣接ノードとするか、 にも依るところです。 状況変化への耐性(resilience)は、 ツリーベースだから、データ駆動だから、ということではなく、 特定のアルゴリズムを想定しての比較が必要なところです。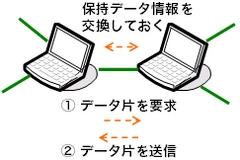
図7 データ駆動 (data-driven, data-centric) 方式
データ駆動方式のALMには、CoolStreaming/DONetやChainsawがあります。 前者は、ノードの情報、例えばIPアドレス等をgossipで流通させ、 隣接ノード数が一定値を切った場合には、 ランダムに選んだノードと接続を持ちます。 各隣接ノードとのスループットに応じて、隣接ノードの選別も行います。 Chainsawは、論文で述べられている範囲では、 ランダムに選んだ一定数のノードを隣接ノードとします。 両者とも、保持データ情報を隣接ノードとの間で交換し、 それに基づいてデータを要求するという点は共通しています。
データ駆動方式は提案から比較的日が浅く、 問題があまり明らかになっていません。 我々の経験と考察によると、 データが各ノードに到達するまでの時間、つまり遅延が問題となり得ます。 これは単に、pull型ゆえにpush型では必要のないデータ要求が必要となり遅延が増す、 というだけの問題ではありません。 遅延と、隣接ノード間での保持データ情報の通知頻度の間にトレードオフがあります。 通知の頻度が低い場合、 自分の隣接ノードがあるデータ片を入手してから、 その入手を自分が知ることができるまで、時間が空いてしまいます。 この時間間隔が、転送の回数だけかさんでしまうわけです。 逆に、通知の頻度を高くすると、それだけ通信処理の負担が増えます。 CoolStreaming/DONetは隣接ノード間で継続的に保持データ情報を交換し、 Chainsawはデータ片を受信すると即隣接ノードにそのことを通知します。 前者は、比較的低頻度、後者は高頻度であると言えます。
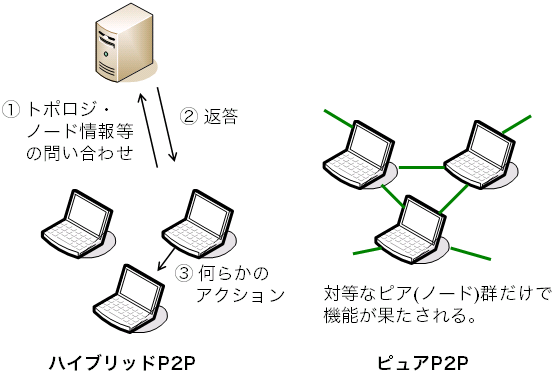
データ転送の方式とは独立して、ALMにも、他のP2Pシステムと同様に ハイブリッドP2PかピュアP2Pかという分類の観点があります。 ピュアP2Pでは、純粋に役割が対等なピア(ノード)群だけで 機能(例:ALM)が果たされます。 それに対してハイブリッドP2Pでは、 ピアに対して何らかのサービスを提供するサーバがあって初めて 機能が果たされます(図8)。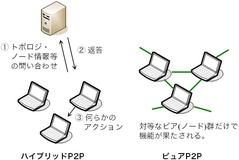
図8 ハイブリッドP2PとピュアP2P
ALMにも、ピュアP2Pの方式とハイブリッドP2Pの方式があります。 ALMの場合、大元のデータ配信元は唯一データを供給する特殊なノードであり、 他のノードと役割が対等ではありません。 これを理由としてALMはすべてハイブリッドP2Pであると分類することもできます。 しかし通常はそうは考えません。 データ配信元ノードが直接サービス(データ)を提供する対象は 全ノードではなく、ごく一部のノードに限られるためです。
ALMの場合、何かしらのサーバがノードの大多数に対してサービスを提供し、 完全に自律的に動作するノードが存在しないかごく少数であるようなものを ハイブリッドP2Pであると分類します。 この基準で分類すると、研究成果として発表されている多くのALMはピュアP2Pです。
ハイブリッドP2PであるALMの例としては、 ツリーベースの方式であって配信木の構造、 すなわちトポロジを集中的に決めるものがあります。 つまり、少数、一般的には1台のサーバが集中的にトポロジを決め、 各ノードに対してどのノードの子になるべきか (およびどのノードの親になるべきか)を指示します。 このようなALMには、CoopNet、ALMIなどがあります。 この方式の利点としては、オーバレイ全体を把握しているコンピュータが トポロジを決めるため、よりよいトポロジを設計し得るという点があります。 ピュアP2Pでは一般に各ノードは全ノードの状況を把握できないため、 よいトポロジの構築は難しいものとなります。 また、トポロジを管理するコンピュータに 全ノードの状況とトポロジ情報が集まっているため、 ALMシステムを運用する人がオーバレイ全体を把握できるという利点もあります。 ピュアP2PのALMでは、オーバレイの全体像を把握するためには、 そのための仕掛けが別途必要となります。
ハイブリッドP2Pの問題は、ALMに限らず、負荷の集中と耐故障性です。 サーバには、オーバレイに参加しているノードの数に対して最低でも比例した 処理負荷とネットワーク負荷がかかります。 データ自体はノード間で転送されますが、 ツリーベースALMではトポロジ管理のための負荷がサーバに集中します。 そのため、そこをいかに軽量に作るかが重要となります。 また、サーバが故障などの理由でサービスを提供できなくなると オーバレイ全体が機能不全に陥るという耐故障性の問題もあります。 ハイブリッドP2Pでは、バックアップサーバを用意するなどの可用性向上策が 欠かせません。
erasure codingは、n個のデータ片に符号化し、 そのうちのk個を揃えるだけで元のデータが復号できるというような符号化を指します。 例えば64個のデータ片に符号化し、そのうちの16個を揃えることで元のデータを 復元できます。 これは特に映像・音声に特化しているわけではありません。
layered codingは、元の映像・音声ストリームを 複数本のデータストリームに符号化します。 受信側は、base layerのストリームだけ受信できれば 最低限の品質での再生が可能であり、 その他のストリームを受信することでより高い品質での再生が可能となります。 例えば、256 kbpsのデータストリーム4本に符号化した場合、 256 kbps分を受信するだけで最低限の再生が可能となり、 1 Mbps分すべてを受信することで最高品質での再生が可能となります。
layered codingによって、広帯域幅かつ高品質のデータストリームに、 狭帯域幅でかつ低品質のデータを兼ねさせることが可能となります。 例えば、ツリーベースのALMで、広帯域幅でつながったノードの先に 狭帯域幅のノードがつながっていた場合を想定します。 この場合は通常、狭帯域幅のノードに合わせて両ノードに低品質のデータを送るか、 それとも、ノードごとに品質の異なるデータを送るかのどちらかとなります。 しかしここでlayered codingを用いることで、 両ノードに個別のデータを送ることなく、 広帯域幅のノードは高品質での再生ができ、 狭帯域幅のノードは帯域幅に応じたのデータを受信して、それなりの品質で再生する、 ということが可能となります。
multiple description coding (MDC)も映像・音声のための符号化手法です。 元のデータストリームを複数本に符号化します。 再生にはbase layerが必要となるlayered codingとは異なり、 任意のデータストリームを最低1本受信すれば 再生できるという再生可能性の高さが特徴です。 データストリームの本数が増えるほど、歪みの少ない高品質な再生が可能となります。 MDCを応用したALMに、CoopNetがあります。
network codingとは、ビット列を伝送する通信ネットワークを前提として、 その中継ノードにおいて中継だけでなく符号化を許すことで、 中継だけが可能な場合よりも高い伝送レートを達成し得るような符号化手法です。 中継ノードで行われる符号化とは、多くの場合、 異なる枝からやってきたデータ同士の線形結合(最も簡単にはx xor y)です。
network codingは2000年にその可能性が示されました。 それ以降、ALMに限定してもすでに多数の応用提案がされています。 おそらく最も話題を呼んだのは、ALMではありませんが、 2005年6月にMicrosoft Researchから発表された P2Pコンテンツ配信方式Avalancheではないでしょうか。 BitTorrentの代替技術といった触れ込みで報道されました。 BitTorrentでは、ファイルをデータ片に分割して、 各ノード(利用者のPC)は全データ片を集めることで元のデータを復元します。 ここで問題となるのが、あまり行き渡っていないデータ片の入手性です。 一片でも入手できないと、元のファイルを復元できません。 そこでAvalancheでは、 データ片そのものの代わりにデータ片の線形結合を流通させることで、 充分な数の任意のかけらを集めることで復元を可能としています。 Avalancheでは、データ片の符号化を配布元のサーバで行う場合と、 ノード上で行う場合の双方が検討されています。 後者を指してnetwork codingと呼んでいます。
ALMシステムの例としてOcean Gridを紹介します。
(略)IPマルチキャストやCDNといった整備された基盤を用いるコンテンツ配信技術には、 運用努力で信頼性を向上させることができるという利点があります。 アプリケーション層マルチキャストには、 設備・費用が安価である、すなわち、誰でも広く発信し得るという利点があります。 これらはそれぞれの性質が活きる領域で使われ、 ときには組み合わされて補完し合いながら使われていくこととなるでしょう。