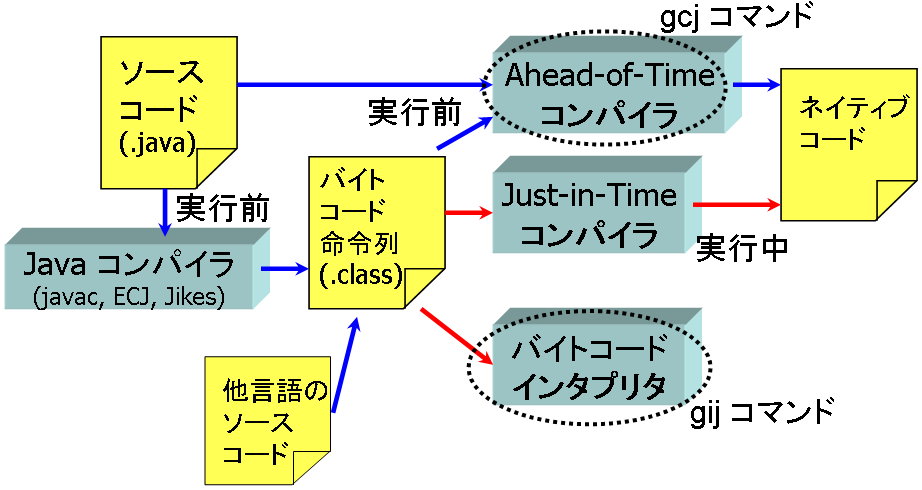
図1: Javaプログラムの実行形態
首藤一幸, "GCCのJavaコンパイラ "GCJ" ガイド", Fedora Core Expert, pp.180-191, (株)技術評論社, 2005年 7月 2日
GCJは、Javaプログラムを実行前にネイティブコードに変換するコンパイラです。 Fedora Core 4には、GCJ、およびGCJでコンパイルされたJavaプログラムが いくつか含まれています。 本稿では、Eclipseといった大きな実用プログラムが動作するくらいに成熟してきた GCJの機能と性能を紹介します。
The GNU Compiler for the Java Programming Language、略してGCJ [1]は、 JavaのAhead-of-Time(AOT)コンパイラです。 GNU Compiler Collection(GCC)の一部として開発されていて、 GCCのJavaコンパイラという位置付けとなっています。 その開発は、Java誕生から約1年半、1996年の10月にすでに始まっていました [2]。 それから9年近くを経てかなり実用的になってきています。 Fedora Core 4はGCC 4.0を採用しており、その一部としてGCJも含まれています。
Javaプログラムを実行する際、通常は javac、ecj(Eclipse Java Compiler)、JikesなどのJavaコンパイラで Javaバイトコードに変換しておいて、 それをJava仮想マシンを使って実行します。 それに対して、GCJはJavaバイトコードではなくてネイティブコードを生成します。 AOTコンパイラという名称は、このように実行前にネイティブコードを 生成してしまうコンパイラを指す言葉です。 生成されたネイティブコードは、プロセッサが直接実行します (図1)。
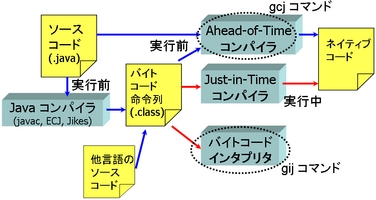
図1: Javaプログラムの実行形態
実行前にコンパイルしてしまうからといって、 Java仮想マシンの恩恵を受けられなくなるわけではありません。 ガーベジコレクタもあります。 GCJは、Boehm GC [3]と呼ばれる、 C/C++用として非常に有名なガーベジコレクタを採用しています。 また、実行前にコンパイル、リンクを行ってしまうにもかかわらず、 プログラム実行中にClass.forName("クラス名")などとして クラスファイルのままのクラスをロード・実行することもできます。 その場合、ロードされたクラスはインタプリタで実行されます。
最近では、Java 2 Standard Edition(J2SE)1.4のAPIもかなりサポートされてきて、 かなり大きな実用プログラムもGCJでコンパイルして動作させることが できるようになってきています。 Fedora Core 2にはGCJでコンパイルされたTomcat 4.1.27が含まれていました。 Tomcatは、非常に広く使われている標準的なJavaサーブレットコンテナで、 JSPエンジンJasperやJakarta Commonsの各ライブラリを含む それなりの規模のソフトウェアです。 これらがすべてGCJでコンパイルされていました。
今回のFedora Core 4には、GCJでコンパイルされたEclipse [4]が含まれています (図2)。 Eclipseは、主にJava言語での開発を対象とした統合開発環境(IDE)です。 NetBeans [5]と並んで広く使われ、活発に開発が進められています。 このEclipseは前述のTomcatも含んでいます。 それ以外にもビルドツールApache AntやテキストサーチエンジンLuceneなどの Java言語で書かれた多くのソフトウェアを含んでいます。 これらすべてがGCJでコンパイルされているわけです。 このEclipse、もちろん、ソースコードの編集からプログラムの実行まで ひと通りの処理をきちんとこなします。
図2: GCJでコンパイルされたEclipse
Fedora Core 4に含まれているGCJ関連RPMパッケージは次の3つです。
基本的に、gcc-javaパッケージが必要とするパッケージを ひと通りインストールすればGCJを使える状態が整います。gcc-java libgcj libgcj-devel
libgcjはGCJでコンパイルしたプログラムの実行に必要なライブラリで、 Javaのクラスライブラリの他、ガーベジコレクタなどを含みます。 つまりこれは、実質的にはJava仮想マシンのようなものです。
また、java-1.4.2-gcj-compat、java-1.4.2-gcj-compat-devel というパッケージをインストールすることで、 Sun Microsystems社(Sun)などが配布しているJDK、Java 2 SDKと同じコマンド名で GCJを使うことができるようになります。 例えばjava、javac、javadoc、jar といったコマンドが用意され、JDKと同じ感覚でGCJを使えるようになります。 しかし、JDKとGCJの双方をインストールしている場合、 どちらが実行されているのかが分かりにくくなる点には注意が必要です。
public class Hello {
public static void main(String[] args) {
System.out.println("Hello World!");
}
}
リスト1: Hello.java
GCJを使うと、Java言語のソースコードをコンパイルして ネイティブコードを得ることができます。 ソースコードではなくて、クラスファイルをコンパイルすることもできます。 カレントディレクトリにあるHello.java(リスト1)をコンパイルするためには、 次のコマンドを実行します。
得られた実行ファイルHelloは、 通常の実行ファイルと何ら変わるところなく実行できます。% gcj -O2 -o Hello --main=Hello Hello.java
% ./Hello Hello World!
GCJの主なコマンドは、コンパイラであるgcjと インタプリタであるgij、この2つです。 gcjコマンドはJava版gccコマンドだと考えてかまいません。 Cコンパイラgccと同様のコマンドラインオプション、 例えば-Oや-o、-c、-l、 -Wなどのオプションを受け付けます。 -cオプションを指定してオブジェクトファイル(.o)を生成し、 それらをリンクする、というように、 C/C++プログラムと同じようにJavaプログラムを扱うことができます。
gcj固有のオプションには、次のものがあります。
--mainオプションは、実行ファイルを作成する際に与える必要があります。 プログラムの実行開始地点であるmainメソッドを含むクラスの名前を 指定します。 -Cオプションを指定すると、gcjはネイティブコードの代わりに クラスファイルを生成します。 つまり、JDKのjavacコマンドと同じ働きをします。
- --main=クラス名
- -C
- --classpath=パス
- --encoding=文字エンコーディング
- -Dプロパティ名=値
その他のオプションは、Javaプログラマにはおなじみの概念、 クラスパスなどを指定するためのオプションです。 JDK、Java 2 SDKでは-Xms、-Xmxで指定する 初期ヒープサイズ、最大ヒープサイズは、それぞれ、 環境変数GC_INITIAL_HEAP_SIZEとGC_MAXIMUM_HEAP_SIZEで 指定します。 バイト単位で、正の整数を指定します。 インタプリタgijに対してはオプションとして指定することもできます。
他にも、Java言語の規則を破ってしまうのですが、 こういった面白いオプションもあります。
後者は、次のコードでも例外が発生しないようにしてしまうというオプションです。
- -fno-bounds-check
配列アクセス時の境界チェックを行わないようにします。- -fno-store-check
ArrayStoreExceptionを発生させるチェックを省きます。
どちらのオプションも、若干の性能向上が見込めます。 しかし、不正なメモリアクセスができないというJavaの利点を捨てることになるので、 普段は使う必要はないでしょう。Object a[] = new String[10]; a[0] = Integer(0);
gcjコマンドに-Cオプションを付けると、 ネイティブコードの代わりにクラスファイル(.class)を生成します。 また、GCJはインタプリタであるgijコマンドも用意しています。 これらは、次のように、JDKで言うところの javac、javaコマンドの代わりとして使うことができます。
% gcj -C Hello.java % ls Hello.class Hello.java % gij Hello Hello World!
このgijと、コンパイラgcjが生成したネイティブコードとは、 相互に呼び出し合うことができます。
Javaが持つ特徴のひとつに、 コンパイル/リンク時にはコンパイラ/リンカが想定していなかったクラスを 実行中に読み込んで実行できるという機能があります。 つまりクラスの動的ロードで、C++とは大きく異なる点です。 例えば次のコードのように、クラス名を文字列として与えてクラスをロードできます。
Class c = Class.forName("クラス名");
この場合、クラス名は文字列で与えられるので、
コンパイラ/リンカは何というクラスがロードされるのか関知できない、
というわけです。
あまつさえ、実行中にプログラムの外から、
例えばユーザに文字列を入力させてクラス名を与えることさえできます。
AOTコンパイラには、こういった動的ロードに対応していないものもあります。 GCJの場合、実行前にコンパイル/リンクされていないクラスであっても、 インタプリタで実行することができます。 逆に、インタプリタで実行されているコードからコンパイル済みのネイティブコードを 呼び出すこともできます。
GCC 4.0から、GCJを Just-in-Time(JIT)コンパイラとしても使うことができるようになりました。 JITコンパイラとは、プログラムの実行中に 実行対象プログラムのコンパイルを行うコンパイラを指します。 Sun、IBM、BEA、その他の主だったJava 2 SE実装は、皆、 JITコンパイラを備えています。
GCJの場合、インタプリタgijでJavaプログラムを実行している最中に、 呼び出されたメソッドが未コンパイルだったなら、 そのメソッドを含むクラスをコンパイルします。 通常のJITコンパイラはメソッド単位でコンパイルを行い、 コンパイル結果はメモリ上に置きます。 それに対してGCJの場合、 コンパイルはクラス単位で行い、コンパイル結果は共有ライブラリとして ファイルシステム上に置きます。 GCJのコンパイル結果はファイルとして残るので、次回以降の実行でも再利用されます。 コンパイルした時点のクラスと実行しているクラスとで内容が一致した場合にだけ 再利用するので、誤ったコンパイル結果を再利用してしまう心配もありません。 この方式を、GCJでは"caching JIT"と呼んでいます。
JITコンパイルを行うためには、インタプリタgijに いくつかのプロパティを与えます。 関係するプロパティは次の3つです。
GCCのマニュアル中に、これらプロパティの説明があります [6]。 しかし、プログラム実行のたびにこれらを手で与えるのは大変です。 リスト2のようなシェルスクリプトを用意するとよいでしょう。 このスクリプトは、JITコンパイルを行うようにgijを起動します。 実行中のコンパイル結果はホームディレクトリの下のgcj-cache/ に収められます。
- gnu.gcj.jit.compiler
gcjコマンドのフルパス。- gnu.gcj.jit.cachedir
コンパイル結果を格納するディレクトリのパス。- gnu.gcj.jit.options
gcjコマンドに与えるオプション。必須ではありません。
#!/bin/sh GCJ=/usr/bin/gcj CACHEDIR=$HOME/gcj-cache OPT=-O2 if [ ! -d $CACHEDIR ]; then mkdir -p $CACHEDIR fi gij -Dgnu.gcj.jit.compiler=$GCJ -Dgnu.gcj.jit.cachedir=$CACHEDIR -Dgnu.gcj.jit.options=$OPT $*リスト2: JITコンパイルを行うようにgijを起動するシェルスクリプト
Javaの標準ライブラリは、登場からJ2SE 5.0(1.5)までの10年の間に膨れ上がりました。 APIリファレンスに現れるパッケージの数は、 JDK 1.0.2ではわずか8でした。それが1.5では実に166にもなっています。 Sunより後発のGCJがこの全体を実装することは困難です。 とはいえ、現時点でも、J2SE 1.4の標準ライブラリのかなりの部分を GCJはカバーしています。 TomcatやEclipseが動作するくらいの範囲をカバーできていることは確かです。
GCJのクラスライブラリは、 GNU Classpath [7]というJava標準ライブラリ実装プロジェクトの成果を 元にしています。 一時期、GCJのライブラリとGNU Classpathはコードの内容が離れてしまって いたのですが、今は再び統合が進んでいます。 このクラスライブラリの開発は、J2SE 1.Xの範囲を完全にサポートしよう、 というような目標で進められているわけではありません。 ライブラリの開発に貢献している人達が、自分達が欲しい部分を実装しています。 最近では、特定のソフトウェアを動作させるという目標が設定されて、 そのために足りない個所を実装していくという進め方で開発が進んでいます。 例えば、Eclipseや、一部Javaが使われているオフィススイートOpenOffice.org 2.0 を動作させることが、目標として設定されてきました。
GCJやその他のJava実装が、 SunのJ2SE実装と比較してどれだけのAPIを実装できているかを 比較するツールがあります。 また、その比較結果はウェブページで公開されています。
Japitools: Java API compatibility testing toolsこれを見ると、どのあたりが手薄なのか見当を付けることができます。
http://www.kaffe.org/~stuart/japi/
J2SE 1.4の範囲で実装されていないのは、例えば GUIツールキットSwingの一部、CORBA関係、Java Soundです。 Java RMIも、プログラムによっては動作しないという状況のようです。 Eclipseは、SWTという、J2SEの標準ではない独自のGUIツールキットを採用している ために、現在のGCJでもきちんと動作します。 GCJはフリー(自由な)ソフトウェアですので、 こういった足りない機能の開発という形での貢献は歓迎されます。
Java言語自体の機能についても、GCJがサポートしているのはJ2SE 1.4の範囲です。 つまり、 1.5の新機能であるGenerics、 Autoboxing、Enhanced for loops、Enumerations、Static Importなどは サポートされていません。 1.4で導入されたAssertion Facilityはサポートされています。
GCC 4.0のGCJを、スループット(速さ)、 アプリケーション起動時間、メモリ消費量など、いくつかの観点から評価します。
まずは、GCJが生成するコードの速さを見ます。 実験環境は、Linux 2.6.8が動作する3.2 GHz Pentium 4搭載PCで、 使ったベンチマークプログラムは次の通りです。
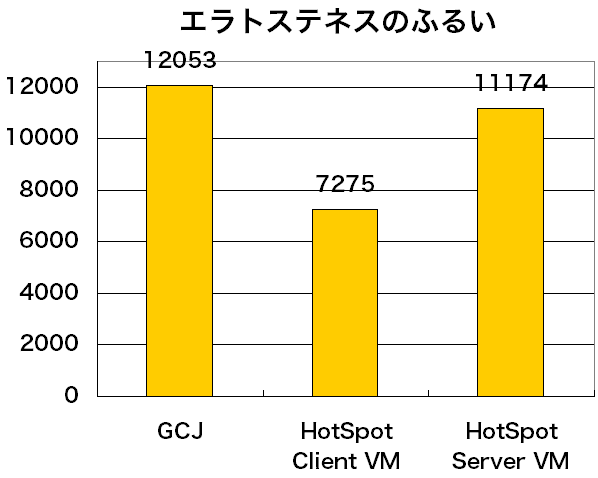
- エラトステネスのふるい
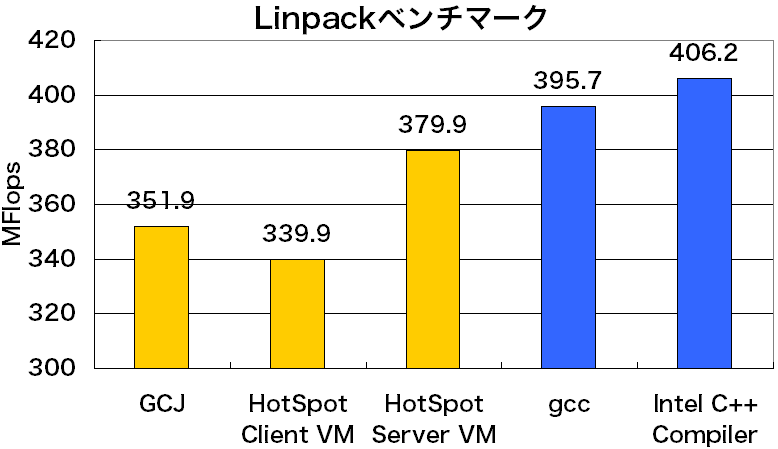
エラトステネスのふるいという方法で素数を求める処理を10秒間に どれだけ行えるかを計測します。 プログラムは、JITコンパイラTYAやJava OS JNodeに含まれる Sieve.javaです。- Linpackベンチマーク [8]
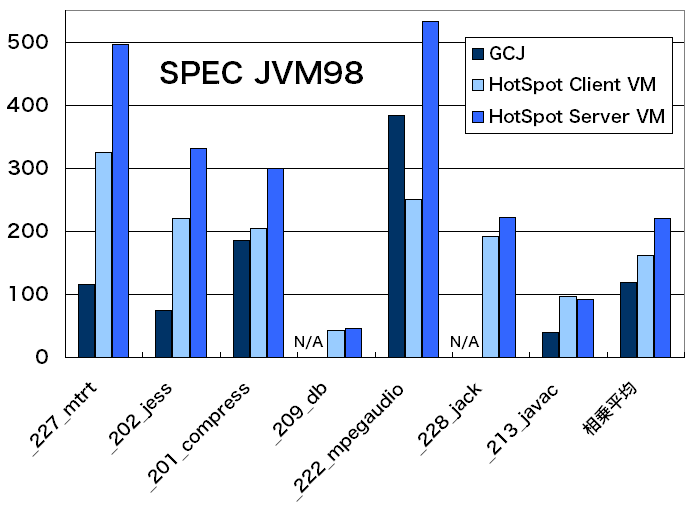
連立一次方程式を解く速さを計ります。 行列のサイズは1000x1000としました。- SPEC JVM98 [9]
いくつかの実アプリケーションを集めたベンチマークです。 相乗平均が総合スコアとなります。
結果は図3〜5、表1の通りです。 すべてのベンチマークで、大きい値が良いスコアです。 GCJには最適化オプション-O2を与え、 クラスファイルではなくJavaのソースコードをコンパイルしました。
比較対象はSunのJDK 1.5.0(5.0)です。 表中にHotSpotなんとかVMとあるのは、 JDK 1.5が持っている2種類のJava仮想マシンです。 HotSpot Client VMはインタラクティブなクライアントソフトウェア向けで、 HotSpot Server VMはサーバサイドのソフトウェア向けとなっています。 それぞれ、javaコマンドに-client、-server オプションを与えて起動します。 このオプションを与えなかった場合には、Client VMの方が起動します。
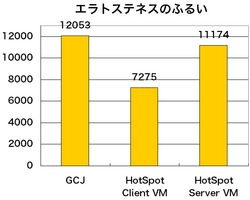
図3: エラトステネスのふるいベンチマークのスコア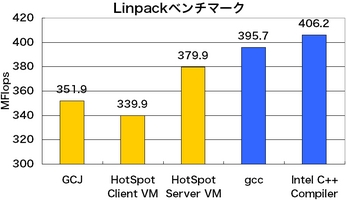
図4: Linpackベンチマーク(1000x1000)のスコア
エラトステネスのふるいやLinpackベンチマークのような ごく限られた種類の処理をひたすら繰り返すようなベンチマークは、 実アプリケーションの性能を見積もるためにはそれほど役に立ちません。 それでも目安にはなります。
これらの結果を見ると、GCJでコンパイルしたプログラムの性能は、場合によっては JDKのHotSpot Server VMにも匹敵するということがわかります。 GCJプログラムをネイティブコードにコンパイルしてしまうのだから JDKよりも性能が高いはず、と期待された方もいるかもしれません。 それは誤解です。 JDKとてJITコンパイラを持っていて、プログラムの実行中にですが、 コンパイルを行います。 JIT(実行中)コンパイル、AOT(事前)コンパイル、 それぞれに有利な点、不利な点があって、 それはもちろん性能に影響するのですが、大勢はコンパイラの出来で決まります。 AOTコンパイラだから出来がいい、JITコンパイラだから出来が悪いということは ないわけです。 もちろん、JITコンパイラには、コンパイル処理にかかる時間がプログラムの実行時間に 加わってしまうという大きな問題があるのですが、 最近のJITコンパイラはこの問題を巧みに乗り越えています(コラム参照)。
Linpackベンチマークについては、C言語で書かれたプログラム(linpackc) のスコアも示しています(図4)(脚注1)。 ここで使ったCコンパイラは、GCC 4.0のgccと Intel C++ Compiler 8.1.028です。 両Cコンパイラに与えた最適化オプションは次の通りです。
脚注1:
Linpackベンチマークの結果(図4)について注意して頂きたいのは、 今回の結果は3.2 GHz Pentium 4の性能を 目一杯引き出しているわけではないということです。 ここでの目的は言語処理系の比較なので、 まったく最適化を施していないJava/Cのソースコードを使っています。
GCJのスコアは、gccの90%近くに達しています。 また、今回扱った中でのJavaとCの最速どうしである HotSpot Server VMとIntel C++ Compilerを比較すると、 JavaはCの93.5%にまで迫っています。 Javaプログラムはインタプリタで実行されるから Cプログラムの何倍も遅い、というのは Javaが登場した1995年からしばらくの間は事実でした。 しかし、これは今となってはまったくの誤解です。 Javaプログラムはたいてい、(JITまたはAOT) コンパイルされた状態で実行されていますし、 gccでコンパイルされたCプログラムよりも JDKの方が速いということもままあります。
もっとも、Java言語の仕様は、 配列の境界チェックや、厳密に定められた例外throwのタイミング、 1次元配列で構成される多次元配列など、 性能上はペナルティとなるような規則を確かに含んでいます。 しかし、昨今のJIT/AOTコンパイラは こういったペナルティをかなりうまく回避しますし、 プログラムの開発効率や保守性など、性能以外の点に目を向けると、 Java言語の厳しめの仕様はむしろ恩恵である場合が多いです。
GCJがFedora Coreに含まれるようになって、 これまでgccが使われてきたような用途にも Java言語を使いやすくなってきたと言えます。
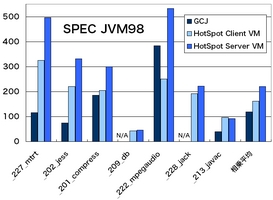
図5: SPEC JVM98のスコア表1: SPEC JVM98のスコア
GCJ HotSpot
Client VMHotSpot
Server VM_227_mtrt 116 325 496 _202_jess 74.9 221 331 _201_compress 186 204 300 _209_db N/A 43.4 46.3 _222_mpegaudio 384 251 533 _228_jack N/A 192 222 _213_javac 39.0 96.1 91.9 相乗平均 119 162 220
SPEC JVM98のスコア(図5、表1)は、SunのJDKには及んでいません。 _222_mpegaudio(MP3デコーダ)では、HotSpot Client VMよりは 良い性能を発揮しています。 _209_db(メモリ上DBの操作)と_228_jack(パーザジェネレータJavaCCの前身)は、 GCJでは正しく実行できませんでした。 _209_dbは、GCC 3.4.2のGCJでは正しく実行できていたので、 GCC 4.0にはまだ改善の余地があるようです。
GCC 4.1に向けた開発版は、4.0よりも明らかに性能が向上しているとも聞きます。 GCC 4.0には、より高度な解析と最適化を狙って、 プログラムの新たな内部表現Tree SSAが導入されました。 この内部表現を活用した最適化は、まさにこれから、 実装、成熟が進んでいくのでしょう。
プログラムや言語のよしあしは、速さ、 つまりコンパイル結果の質だけでは決まりません。 ここでは、速さ以外の観点からGCJを評価します。 実験環境はLinux 2.6.11が動作する3.2 GHz Pentium 4搭載PCです。 GCC 4.0の比較対象としては、 SunのJDK 1.5.0 Update 3に加えてIBMのJDK 1.4.2 SR1aを用意しました。
長年、JDKの問題とされてきたのが、 プログラムの起動にかかる時間やユーザからの入力に対する応答性です。 プログラムの起動時には特に多くのクラスがJava仮想マシンにロードされるので、 JITコンパイルが多く起きて、時間を食いがちなのです。 Sunの場合、速さ第一のHotSpot Server VMに加えて、 応答性を重視したHotSpot Client VMを提供することで、 この問題に対応してきました。 IBMの場合は、単一のJava仮想マシンで両方を満たそうとしています。
GCJは基本的にAOTコンパイラであり、特にJITコンパイラとして使わない限りは 実行中のコンパイルは行わないので、応答性の良さが期待できます。
ここではEclipseの起動に要する時間を測りました。 Eclipseはそれなりの規模を持った実用プログラムですので、 これを素早く起動することは容易ではありません。 また、非常に広く使われており、 その起動時間は多くのユーザの経験するところなので、 これを短縮することの意義は大きいです。
表2に、GCC 4.0のGCJと各種JDKでのEclipse 3.1M6の起動時間を示します。 計測はストップウォッチを使って手で行ったので、 結果はおよその時間となっています。
表2: Eclipseの起動時間
HotSpot Client VM 8 秒 IBM JDK 1.4.2 SR1a 10.5 秒 HotSpot Server VM 11.5 秒 GCJ 19 秒
期待に反して、 GCJでコンパイルされたEclipseの起動は遅いという結果になってしまいました。 この原因として,GCJ開発者のひとりは、 リンカ・ローダ(ld.so)が時間を食っているという予想を立てています。 GCC 4.0より前の版のGCJでは、 SunやIBMのJDKを使った場合よりも素早く起動していたと聞きますし、 今はライブラリの外に見せてしまっているシンボルを減らすことで リンカ・ローダの作業を大きく減らせるとのことなので、 今後大幅に改善される見込みはあります。
次は、メモリ消費量です。 ほとんど何もしないJavaプログラムが起動した状態でのメモリ消費量と、 Eclipse起動直後の消費量を測りました。
メモリ消費量を表す数値としては、psコマンドで表示される RSS(resident set size)を採用しています。 この値は、メモリが不足してページアウトが起きると プログラムが使っているメモリ量よりも小さくなってしまいます。 そのため、正しい値が得られていることを確認するために、 実験の最中にページアウトが起きていないことも確認しました。
表3、表4にそれぞれ、ほとんど何もしないJavaプログラムのメモリ消費量と、 Eclipse 3.1M6起動直後のメモリ消費量を示します。 前者については、gcjコマンドでコンパイルした場合に加えて、 インタプリタgijで実行した場合の値も示しています。 Sun JDKとしては、HotSpot Client VMを使いました。 Eclipse起動時のJava仮想マシンの初期ヒープサイズは40 MBに揃えました。
表3: ほとんど何もしないJavaプログラムのメモリ消費量
gij 9.5 MB Sun JDK 9.7 MB gcj 11.2 MB IBM JDK 14.6 MB
表4: Eclipse 3.1M6のメモリ消費量
IBM JDK 100.6 MB Sun JDK 110.1 MB GCJ 138.0 MB
どちらの場合でも、gcjでコンパイルした場合には Sun JDKよりも多くのメモリを消費しています。 これについてはGCJがメモリを多く消費しているというよりも、 JDKが、JITコンパイル対象を絞るなどして消費メモリを節約している(コラム参照) と見るべきでしょう。
もっとも、GCJの場合、この消費メモリのうち共有ライブラリ(.so)が 占める部分は他のプロセスと共有することができます(コラム参照)。 そのため、同一マシン上で複数のJavaプログラムを起動する場合には ある程度の節約効果が見込めます。
表5: GCJ、各JDKのディスク占有量
GCJ 30.8 MB IBM JDK 1.4.2 SR1a 85.7 MB Sun JDK 1.4.2_07 94.1 MB Sun JDK 1.5.0_03 139.6 MB
インストールされた状態のGCJがどのくらいのディスクを占有するのか調べました (表5)。 GCJの値は、RPMパッケージ gcc-java、libgcjがインストール済みの状態で占有する ディスクの分量です。 これらは、GCJ自体、および、コンパイルしたプログラムを動作させるために 最低限必要となるRPMパッケージです。
GCJより機能の多いJDKがより多くディスクを占有するのは当然ではあります。 また、GCJはGCCの基本部分(gccパッケージ、4.8 MB)を必要とするので、 それも含めたディスク占有量を考えるべきかもしれません。
GCJのファイルのうち、特に大きいのは共有ライブラリlibgcj.so.6.0.0です。 GCJ関連ファイル30.8 MBの50%以上となる16.3 MBを占めています。 これは、Javaのクラスライブラリをコンパイルしたものの他、 ガーベジコレクタなども含んでいます。 つまり、JDKであればJava仮想マシンが提供する機能も含んでいるわけです。 GCJなどのAOTコンパイラでコンパイルしてしまえばJava仮想マシンは不要、 というのは誤解であって、Java仮想マシンが提供する機能の多くは、 依然として必要なのです。
とはいえ、GCJはフリー(自由な)ソフトウェアですので、 不要なクラスは自分の手で省いてかまいません。 ライセンスに従う限り、 そうやってスリムにしたものを製品に組み込むことも許されています。
本稿では、GCJの機能、使い方、また、性能その他の観点からの 評価結果を紹介しました。 母体であるGCCが4.0という新たなフェーズに入ったことで、 性能的、機能的に改善の余地が残っている状況ではありますが、 標準的に使われているSunやIBMのJDKと比較してもまずまずの 性能と機能を達成しています。 GCJでコンパイルされたEclipseが動作しているという事実は、 GCJの成熟度合いを示しています。
シビアな目で見ると、今後の向上が見込まれるとはいえ、 性能やアプリケーション起動時間ではSunやIBMのJDKに及んでいません。 それではGCJの意義はどこにあるかというと、 ひとつはFedora Coreに同梱されているという点でしょうか。 OSの付属ツールだけでJavaプログラムの開発、実行ができるようになったわけです。
もうひとつは、GCJがフリー(自由な)ソフトウェアだということです。 ソースコードを入手、改変して、自分の目的に使ったり配布したりできる ということもありますし、 他のソフトウェアとともに配布しやすいという効果もあります。
フリーソフトウェア運動を創始した Richard M. Stallman氏に至っては、 多くのフリー(自由な)JavaプログラムがSunなどによる自由ではない Java実装に依存してしまっている現状を"The Java Trap" [10]とすら呼んでいます。 オープンソースのオフィススイートであるOpenOffice.org (OOo) 2.0が Java言語で書かれたコードを含んでいることを氏が知った結果、 フリーソフトウェア推進団体FSFは、 OOoのJavaなしバージョンの面倒を看るボランティアを募集しました。 この件は、結局、Java部分をGCJで動作させる取り組み [11]を始めようということで 決着が着きました。
このように、フリーソフトウェア推進派にとって GCJは大きな意義を持っています。 また、ライセンス的にはフリーソフトウェアは オープンソースソフトウェアでもあるので、 オープンソース推進派にとってもGCJの存在には意義があるでしょう。 例えば、GCJが使っているクラスライブラリGNU Classpathは、 オープンソース開発団体Apache Software Foundationの Java 2 SE開発プロジェクト Harmony [12] にて、採用が検討されています。
ともかく、今やFedora Coreは実用的なJava処理系、実行系を持っています。 フリーソフトウェア、オープンソース擁護派も、そうでない皆さんも、 是非、お試しください。
GCJは基本的にはAOTコンパイラです。実行前にコンパイルを済ませます。 それに対して、Sunなどが配布しているJDKは、プログラム実行中にコンパイルを行う JITコンパイラを備えています。 AOTコンパイラとJITコンパイラ、それぞれに有利な点、不利な点があり、 一概にどちらがいいと言えるものではありません。
まず、JITコンパイラの大きな問題として、 コンパイル処理に要する時間がプログラムの実行時間に加わってしまうという 問題があります。 例えば、コンパイルに1秒かかったコード片の実行時間が (インタプリタなどと比較して)0.1秒だけ速くなったとしましょう。 このコードは、その後10回は実行されないと、 コンパイルは割に合わなかったということになってしまいます。 1回しか実行されなければ0.9秒の損になります。 しかし、もし100回実行されれば9秒の得となるわけです。
質の良い高速なコードを生成するためにはコンパイル処理に時間がかかるものですが、 JITコンパイラの場合、コンパイル時間はできるだけ切り詰めなければなりません。 そのためには、効果のある最適化手法であっても、 その効果が最適化に要する時間に見合わないようならば 採用/適用を見合わせることすらあります。
JITコンパイルによって得をするためには、 その後何度も実行されるコード(たいていはメソッド単位)を見つけて、 そういったコンパイルする意義の大きいコードに限ってコンパイルするという 選択が重要です。 あるコードがその後何回実行されるかは知りようがないので、 それまでに(インタプリタで)何回実行されたかを数えておいて、 多数回実行されたコードをJITコンパイルの対象とします。 多数回実行されたコードはその後も何度も実行されるだろうという 経験則に基づいた予測をするわけです。
このように、実行される回数の多い個所、つまりhot spotを重点的に 最適化する技術を指してSunは"HotSpot"と呼んでいます。 "Java HotSpot"はSunの登録商標ですが、こういった技術自体は Sunだけが採用・実装しているわけではありません。 IBM、BEA他、他のJ2SE実装も、同様の手法を使っています。
一方、AOTコンパイラにはコンパイル時間の問題はありません。 プログラムの実行前にコンパイルを済ませてしまうので、 いくらでも、と言っても限度はありますが、 コンパイル処理に時間をかけることができます。
このように、JITコンパイラの方が不利ではあるのですが、 最近のJITコンパイラはコンパイル対象をしっかりと限定することで、 この問題を巧みに乗り越えています。
JITコンパイルによる利得は高速化ですが、 損失はコンパイル時間だけではありません。 コンパイル結果のネイティブコードを保持するために必要となるメモリも 損失のうちです。 もっとも、AOTコンパイラとて、 コンパイルしたネイティブコードはメモリにロードする必要があります。
メモリ消費量についてJITコンパイラが有利な点は、 前述のようにコンパイル対象を限定することで、 コンパイル時間だけでなくてコンパイル結果が消費するメモリも 節約できるということです。 JITコンパイルの結果として得られるネイティブコードは Javaバイトコードの3倍かそれ以上の大きさになるので、 この効果はばかにできません。 と言っても、AOTコンパイラであっても、 GCJのようにインタプリタを呼び出すことができるのであれば、 プログラムの全体をコンパイルしておく必要は必ずしもありません。 コンパイルしておかなかったクラスはインタプリタで実行すればよいわけです。
また、Javaバイトコードをメモリに持つ必要がないという点ではAOTコンパイラが 有利に見えます。 しかし、コンパイル結果のネイティブコードと比べると Javaバイトコードは小さいので、メモリ消費量への影響も 比較的小さなものとなります。
AOTコンパイラには別種の強みがあります。 コンパイル結果を共有ライブラリ(.so, .DLL)にしておけば、 複数のプロセスがメモリ上でその共有ライブラリを共有できるので、 消費メモリの節約になります。 この方式はJITコンパイラでも出来ないことはありませんし、 現にGCJがJITコンパイラとして働く際にはこの方式で動作します。 しかしこれはJITコンパイラでは一般的な方式ではありません。
JITコンパイル方式を採っているSunのJDKも、 これと似た工夫をしています。 JDK 1.5に導入されたClass Data Sharing [13]がそれです。 標準ライブラリ中のよく使われるクラスを、 Java仮想マシンにロードされた後のメモリ上の状態で、 ファイルに書き出しておきます。 Java仮想マシンを起動する際には、そのファイルをメモリにマップ (UNIX系OSではmmapシステムコール)します。 このメモリ空間は同一コンピュータ上の複数のJava仮想マシンによって 共有されるので、複数のJava仮想マシンが個別に持つよりもメモリを節約できます。 また、この仕掛けによって多くのクラスを一括してメモリに読み込めるので、 個々のクラスを解釈しながらJava仮想マシン内に読み込むよりも、 時間を節約できます。
さらに進んだメモリ節約手法としては、単一のプロセス内に 仮想のJava仮想マシンを複数用意するMulti-Taskingという手法 [14]があります。 実装としては、HotSpot VMを元にしたMVMという研究上の実装の他に、 携帯電話機程度の環境を対象としたJava仮想マシン CLDC HotSpot Implementation(CLDC HI)があります。
このように、Java仮想マシン単体でのメモリ消費量については、 原理的には、AOTとJITのどちらが有利ということはありません。 JITには、コンパイル対象を限定して自動的にメモリを節約できるという強みがあり、 一方AOTには、OSが提供するプロセス間メモリ共有のための機能を 素直に活用しやすいという強みがあります。
こうしてみると、JITコンパイラが有利な点の方が少ないようですが、 必ずしもそうとは言えません。 プロセッサにもOSにも依存しないJavaバイトコードを実行できるという 機種非依存性がJavaの大きな特徴のひとつですが、 AOTコンパイラを使う場合、機種ごとにコンパイルを行っておく必要があります。 当然、コンパイル結果を他の機種に移しても動作しません。 AOTコンパイルの結果得られるネイティブコードはJavaバイトコードよりも大きく、 それをディスクに保持しておく必要もあります。
また、原理的には、JITコンパイラは、プログラム実行中だからこそ知ることのできる、 今まさに実行されているプログラムの特性をコンパイル処理に活かすことができます。 具体的には、コード片の実行頻度や条件分岐の方向を反映したコード片の配置、 よく同時に使われる複数のデータがプロセッサのキャッシュにうまく載るような配慮、 といった最適化が考えられます。 前述したコンパイル対象の選択も、 JITの強みというよりも弱点をカバーするためではありますが、 実行中だからこそ得られる情報(実行頻度)を活用しています。 AOTコンパイラでも、Profile-Guided Optimizationといって、 プログラムの振る舞いを事前の実行で調べておいて、 その情報に基づいて最適化を行うことができるものもあります。 しかしJITの場合、事前に振る舞いを調べる手間なく、 特定のプログラムの特定の実行に特化した最適化ではなくて、 まさにそのときどきの状況に応じたコンパイル処理ができるわけです。
原理的なことを言うなら、AOTコンパイラには、 高級言語の構造、主にループを把握して コンパイルに活かせるという有利な点もあります。 あまり行うものではありませんが、ループ構造を把握することは ベクトル化や並列化の第一歩です。 Javaバイトコードを入力とするJITコンパイラとは違い、 AOTコンパイラにはJava言語のソースコードを読み込むチャンスがあるので、 ソースコードから素直にループの構造を知ることができます。 もっとも、Java言語に限って言うならば、 Javaバイトコード命令列から元となるソースコードの構造を 復元(逆コンパイル)する手法も知られています。 なので、JITコンパイラが高級言語の構造を把握することも可能ではあります。 実際、最近のJITコンパイラは、逆コンパイルというほど徹底してはいないものの、 ループの誘導変数(for (i=...)のi)を識別して最適化に活かす、 くらいのことは行っています。