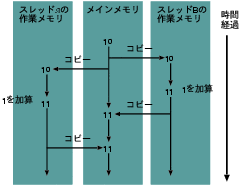
図1: レース状態: 複数の操作
首藤一幸, "マルチスレッドプログラムに対するデバッギングの心得", 月刊ジャバワールド 2002年 1月号, pp.64-73, IDGジャパン, 2001年 11月
スレッドは近代的なプログラミング言語やソフトウェアにとって 不可欠の概念、技術であり、 特にJava言語を使うプログラマであればこれを避けて通ることはまずできない。 スレッドに関係したバグは発見が難しく、また、問題の再現すら おぼつかないことが多い。 そのため、きちんと知識を持って開発に望み、 バグを作らないことが大切となる。 マルチスレッドプログラムでは、なぜ、どういった問題が起こり得るのか を知ることで、多くのバグを事前に回避できるだろう。 これはデバッグにも必要となる知識である。 実際のデバッグで役立ついくつかの技法も紹介する。
Java言語で開発をする場合、スレッドはまず避けて通れない。 Javaはそれまでの多くのプログラミング言語とは違って、初めか らスレッド機能を持ち、Java仮想マシンからクラスライブラリ、 アプレット、Servletエンジンまで、スレッドを前提として作られている。 そのため、ある種の処理はスレッドを使って記述することが前提となっているし、 マルチプロセッサを活用するためにもスレッドは必須である。
複数のスレッドが走るプログラムのデバッグは確かに難しい。 スレッドを使うことで、確かにある種のプログラムは見通し良く素直に書ける。 しかし、処理の流れがひとつだったときには起こらなかった 新たな問題が起きてくることも事実である。 マルチスレッドプログラムは同期と排他制御をきちんと行わないとまともに動作せず、 しかも、問題が発覚してからのデバッグが難しいので、 プログラマはきちんとした知識を持って開発に取り組まねばならない。
このように、スレッドはたやすい相手ではないが、かといって必 要以上に恐れる必要はない。どんな問題が起き得るのか、どうす れば問題を避けられるのかという基本さえおさえておけば、 たいていの問題は事前に避けられる。 当然、こういった知識は問題解決、つまりデバッグにも必要なものである。 まずは、マルチスレッドのプログラミング、デバッグの際に 知っておくべきことを述べていく。
マルチスレッドといっても、もしスレッド間で データを共有する必要がなければ何も難しいことはない。 その場合、ひとつひとつのスレッドが独立したプログラムのようなものなので、 マルチスレッドならではの注意は何も要らない。 しかし、そういった各スレッドの独立性が高いプログラムであっても、 何かしらのデータは共有するものである。 例えば、ネットワーク経由で何かのサービスをするサーバプログラムでは クライアントごとに面倒を看るスレッドを作ることが一般的で、 スレッド間ではあまり密にデータのやりとりをする必要はないものである。 しかしそれでも、チャットサーバであれば発言内容を 他のスレッドに伝える必要があるだろう。 ほとんどデータの共有が要らないウェブサーバでさえも、 スレッドを無制限に作ってしまわないために稼働中のサービススレッドの数を スレッド間で共有する必要があるだろう。
図1: レース状態: 複数の操作
『複数スレッド間でデータを共有すること』がすべての問題の根源である。 共有されているデータを操作する際に 他のスレッドから横やりが入るとたいていはまずいことが起こる。 図1を見て欲しい。 2つのスレッドAとBがひとつのカウンタ、つまり整数型の変数を共有し、 どちらのスレッドも値を1増やそうとしている。 しかし、運が悪くタイミングが衝突してしまったために、 本来なら最終的な値は12になって欲しいところ、11になってしまった。 かといって、このJava仮想マシン(JVM)に問題があるわけではない。 きちんと仕様に沿って作られたJVMでもこういった現象は起きる。 こういった問題が起きないようにプログラムを書くことは、 完全にアプリケーション開発者の責任である。
図1でスレッドAとBが行っている処理は、ソースコードでは次のようなものである。
object.value++;
ここでobjectはあるオブジェクトへの参照であり、 valueはそのオブジェクトの整数型のインスタンス変数である。 ++という操作がひとつ書かれているだけなので、 一見、他のスレッドからの横やりなど入らない アトミック(atomic)な操作に見えるかもしれないが、実はそうではないのである。
マルチスレッドプログラムを書く際は、常に 「もしここで他のスレッドに割り込まれて値を変更されたら…」と いうように、想像力を働かせて最悪の場合を想定しながら開発を進める必要がある。 1,2回の実行で使い捨てるプログラムならともかく、最悪の場合こそ 最悪のタイミングで起こるものである。
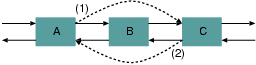
図2: レース状態: 双方向リスト
このような、スレッドがどのようにスケジュールされるかという タイミングによって発現する問題を、レース状態(race condition)という。 スレッドAとBが競走しているような状態であ ることから付けられた名前である。レース状態は、図1の場合で は、読み込み、加算、書き出しという複数の操作を 単一の変数に対して施す際に起きたが、 操作対象が複数である場合にも起き得る。 例えば、図2のような双方向リストがあったとする。 ノードBを削除するには、ノードAがCを指すようにして(1)、また、 ノードCがAを指すように(2)リンク先を2ヶ所変更しなければなら ない。ここで、(1)の変更後、(2)の変更が済む前に、別のスレッ ドがこのリストに変更を加えたらどうなるだろうか。例えば、ノー ドAが削除されたら…リストはおかしな状態になってしまう。プ ログラムが異常終了するか、もっと悪ければ、利用者のデータが 壊れてしまうかもしれない。
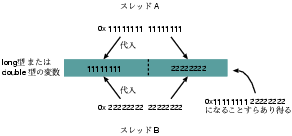
図3: 64 bit変数への代入はアトミックではない
Java言語、JVMではどんな操作がアトミックなのか、 つまり他のスレッドからの横やりが入らないうちに完了できる操作は何なのか。 もしこれに興味があるなら、Java言語仕様第2版の第17章(仮想マシン仕様第2版の第8章) 「Threads and Locks」を読んで欲しい。 Javaのメモリモデルでは、スレッド間で操作を確実に順序付けるためには synchronizedキーワードを用いたロックが不可欠である。 演算結果をメインメモリに反映させるため、つまり、 他のスレッドに見せるためにすら、synchronizedは必須である。 共有データを操作する際にsynchronizedの記述をサボれるとは 考えない方がいいだろう。 例えば、64 bitであるlong型、double型の変数に 値を代入する操作すらアトミックだという保証はない。 2つのスレッドから64 bitのインスタンス変数に代入を行った場合、 2つの値が混じってまったく別の値が残ることすら起こり得る(図3)。
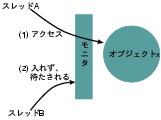
図4: モニタ
レース状態を避けるには、あるデータに対する一連の操作中に 横やりが入らないようにしなければならない。 そのために、Java言語にはモニタ(monitor)という機構が用意されている。 『synchronized』が、その、モニタを利用するためのキーワードである。 あるモニタに同時に入れるのはひとつのスレッドだけ、という機構である。 図4は、スレッドAがオブジェクトxのモニタに入っているため、 スレッドBは入ることができずに待たされている、という状況である。 この後、スレッドAがモニタを出ると、待っていたスレッドBに通知が届き、 今度はBがモニタに入ろうとする。 以下では、読みやすさのために、モニタに入る、モニタを出ることを指して、 ロックやモニタを獲得、解放する、と書くことがあるので注意して欲しい。
図1の問題を避けるには、共有データにアクセスする前に、 操作対象のオブジェクトのモニタを獲得しておき、 操作が済んだらモニタを解放すればよい。 つまり、synchronized (操作対象オブジェクト) { 操作 } というように一連の操作をsynchronized文のブロックに入れるか、 操作を行うメソッドにsynchronized修飾子を付けるのである。
図2の問題への対策は図1よりもう少し複雑で、 何をロックするのかをしっかり考えねばならない。 削除するノードBだけをロックしてもレース状態は防げない。 例えば、あるスレッドがBを削除しようとしている最中に、 別のスレッドがAやCを削除したらやはり問題は起きる。 リスト全体を代表するオブジェクトをロックすることになるだろう。 リストが長大である場合、リスト全体をロックするよりは 一部分だけをロックしたいと考えるのは自然なことである。 これによって、リストの異なる部分を複数のスレッドが同時に操作できるようになり、 性能を向上させられる可能性がある。 しかしこの挑戦によってプログラムは複雑になり、レース状態の危険が増す。 こういった挑戦をするか否かは、 デバッグや保守のコストまで含めて総合的に判断すべきで、 既存の、安全性がすでに検証されたライブラリがあるならそちらを使うことも 検討すべきであろう。
そもそもスレッド間でのデータの共有が問題を起こすのだから、 共有データは極力少なく設計しておくことも大切である。 また、なるべく共有しにくい種類の変数を使うという原則に従うことも有効である。 ここで種類と言っているのは、ローカル変数、インスタンス変数、クラス変数 という種別である。 ローカル変数、インスタンス変数、クラス変数という順で 共有しにくいと考えてよい。 以下では、int型の変数について考える。 ローカル変数であれば決して他のスレッドから値を変更されることはない。 つまり、レース状態を心配してロックする必要はまったくない。 しかしインスタンス変数となると、オブジェクトへの参照を持っている スレッドからはアクセスできるので、他のスレッドから変更される恐れが出てくる。 クラス変数ともなると、どのスレッドからもアクセスされる恐れがあると 考えねばならない。 クラスオブジェクトへの参照はjava.lang.ClassクラスのforName()メソッドや <クラス名>.class構文で容易に手に入るからである。 もっとも、intなどの基本型ではなくて参照型の変数の場合は、 ローカル変数であってもそれが指しているオブジェクトは 他のスレッドからも参照されていて、共有しているかも知れないということは 忘れてはならない。
また、共有しにくい種類の変数ほど、一般に、JITコンパイラによる最適化で 有利だということも覚えておいて損はないだろう。 性能上の理由からも、極力共有しにくい種類の変数を使うべきである。
Java言語で用意されているモニタには、次の特徴がある。
synchronized (java.lang.Integer.class) {
…
}
当然ながら、配列もオブジェクトであるためロックすることができる。
あるsynchronizedが何をロックするのかをきちんと把握しておかないと、 デバッグはおぼつかない。 例えば、synchronized (<式>) {…} と書いた場合、<式>が指す オブジェクトのモニタが獲得されるということは判りやすいが、 メソッドの場合は注意が必要である。 インスタンスメソッドの宣言にsynchronized修飾子を付けた場合、 呼び出し時にロックされるのは、呼び出しのターゲットとなる オブジェクトのモニタである。 では、クラスメソッドの呼び出しではどうか。 そのクラスに対応するjava.lang.Classクラスのオブジェクト、 つまりクラスオブジェクトのモニタが獲得される。 クラスオブジェクトへの参照は上述の通り容易に手に入るため、 安易にロックしない方がよい。 あなたがロックしようとしているクラスを、 別の共同開発者は別の目的でロックしようとするかもしれない。 運が悪いと、デッドロックの原因となる。
次の特徴、何度でも獲得できる、とはどういうことか。 あるスレッドが次のコードを実行する際、
synchronized (obj) { …(1)
…
synchronized (obj) { …(2)
…
synchronized (obj) { …(3)
…
} …(4)
…
} …(5)
…
} …(6)
まず(1)にてobjが指すオブジェクトのモニタを獲得する。
(2)にさしかかると、再び同じモニタを獲得しようとする。
ここでミューテクス(mutex)といった単純なロック機構であれば、
ロックは(1)にてすでに獲得されてしまっているために、
(2)では獲得できずに待たされることになる。
しかし、Java言語のモニタは
再入可能であるため、(2)や(3)で待たされることはない。
(2)、(3)では、モニタ内部にあるロック回数のカウンタが増やされるだけで、
スレッドは実行を続けられる。
(4)、(5)、(6)とsynchronized文のブロックを抜けるときに
カウンタの値は減らされ、これが(6)では0になり、ここでロックは完全に解放される。
ライブラリやAPIではなくてJava言語自身がsynchronizedという構文を持っている ことは、ロックの解放し忘れを防止するという、非常に大きな効果を発揮している。 Java言語のモニタは、データへのアクセスを排他的に行うための 相互排他に利用できる。 C言語でスレッド間の相互排他を行うためには、UNIX系のOSであれば POSIXスレッドAPIのpthread_mutex_lock()など、 Win32であればWaitForSingleObject()、ReleaseMutex()といった関数を 呼び出してmutexロックを利用することが一般的である。 C言語自身には同期をサポートする構文がないため、 相互排他を行うためには関数を呼び出さねばならない。 ここでもし、解放のための関数呼び出しを書き忘れると大変なことになる。 プログラムが正常に動くことはないだろう。 この「解放し忘れ」というミスはごくごく簡単に犯しがちである上に、 発見が難しい。基本的に目でプログラムを追って検査するしかない。 条件分岐先の一方にしか解放処理を書かなかったり、 ファイルのオープン失敗といったエラー発生時に解放し忘れたり といったミスはよく犯しがちである。 Java言語では、synchronizedメソッドからreturnする際や、 synchronized (…) {…} 文のブロックから抜ける際には 確実にモニタが解放される。 ここにも、まずいプログラムを書きにくくして生産性を高くする、 というJava言語の設計思想がよく表れている。
ロックすれば万事解決かというと、残念ながらそうでもなく、 また別の危険が待っている。 ロックの仕方を間違えると、複数のスレッドがお互いを待ち合って プログラム全体が止まってしまうことがある。 この現象をデッドロック(deadlock)という。
public class Account { // 口座クラス
private int amount; // 残高
…
/** 送金メソッド */
public synchronized void transfer(
Account target, int amount) {
synchronized(target) {
this.amount -= amount; // 引き落とし
target.amount += amount; // 振り込み
}
}
…
}
リスト1: 銀行口座間で送金を行うメソッド
例として、銀行口座間の送金(リスト1)を考える。 口座を表すAccountクラスは、送金のためのtransfer()メソッドを持っている。 口座suzukiから口座tanakaに10万円送金するには、次のように書く。
送金中に他のスレッドが残高を変えてしまうことのないように、 transfer()メソッドは、送金に先だって 送金元と送金先、2つの口座のモニタを獲得しようとする。 2つのモニタ獲得に成功すると、送金元の残高を減じ、その分を送金先の残高に加算し、 モニタを解放してreturnする。suzuki.transfer(tanaka, 100000);
実はこのtransfer()メソッドはデッドロックを引き起こし得る。 現場でこういうコードを書いてはいけない。 ここから先に読み進む前に、どうしてデッドロックが起こるのか考えてみて欲しい。 そして、もしわからなければ悔しがって欲しい。
次の状況を考える。 スレッドAが口座suzukiからtanakaへ送金しようとしているときに、 別のスレッドBが逆方向に、つまり口座tanakaからsuzukiへ送金しようとする。 スレッドAはまず口座suzukiをロックし、続いてtanakaをロックしようとする。 スレッドBは逆の順でロックを試みる。 もし、スレッドAがsuzukiのロックに成功し、しかしtanakaをロックできる前に スレッドBがtanakaをロックしてしまったらどうなるだろう。 スレッドAはtanakaのロック解放を待ち、逆に、スレッドBはsuzukiのロック解放を 待ち続ける、永遠に。果たしてAとBはデッドロックに陥った。
デッドロックの原因は、複数のモニタをスレッドごとにバラバラの順番で 獲得しようとすることである。 対策は何通りか考えられる。
そもそもモニタは複数獲得しないという対策も有効である。 その場合、それではまったくロックしないというわけにもいかないので、 より上位の、包括的なモニタを獲得することになる。 具体的には、個々の口座をロックするのではなく銀行自体をロックする、 といった具合いである。 銀行の例では、実際には2口座間の送金だけのために 銀行全体をロックしてしまうわけにはいかないのだが、 場合によっては有効な方策である。 ロック対象が減ることでプログラムをシンプルにできるので、 バグを作ってしまう危険を下げることができる。 複雑さはやはりバグの温床である。
どのくらい包括的な範囲をロックするか、 つまりロックの粒度をどのくらい粗く、または細かく設定するかは、 シンプルさと性能の間のトレードオフである。 一般に、包括的に粗い粒度でロックすると、プログラムはシンプルに なってバグの危険は減るものの、 他のスレッドの動作を妨げる機会が増えて全体の性能は低下する。 粒度が細かいとその逆である。 粒度の決定は場合によって最適な選択が異なる、 設計方針に属するごく工学的な問題である。
デッドロックが起きるシナリオとして、 スレッドがロックを保持したまま異常終了してしまう、というケースを 危惧する向きがあるかもしれない。 確かに、 C言語でPOSIXスレッドAPIやWin32 APIを使ってスレッドプログラミングをする場合、 ロックを解放しないまま終了するのは簡単であり、 その永久に解放されないロックを待つことによるデッドロックも簡単に起こせる。 しかし、Javaではこの心配はまず不要である。 確実に解放されるというのは、モニタの大きな利点である。
スレッドが正常系から外れて実行を終了する場合というのは、 以下の場合であろう。
最後のdestroy()メソッドだけは不安が残る。 メソッドの説明に「クリーンアップなしでスレッドを破壊する」と 書いてあり、モニタの解放もせずに破壊する仕様となっていることがうかがえる。 しかしこのdestroy()メソッドは、少なくともSun社のJava実行系では 実装されたことがない。 Java 2 SE 1.3.1でも1.4 Beta 2でも実装されておらず、 メソッドの説明でも「実装されていない」と明言されている。 このメソッドは、おそらくSun社以外の実装でも実装されていないことが 多いのではなかろうか。 destroy()メソッドによってデッドロックが引き起こされる危険は、 実際にはまずないと考えられる。
もっとも、stop()メソッドによって直接的にロックされたままのモニタが 残ってしまうことはないからといって、 stop()には使うべきではない別の理由がある。 あるスレッドがstop()で止められると、そのスレッドが保持していたロックは 強制的に解放されてしまう。 ロックしていたということは、レース状態を避けるために 何かのデータを保護していたはずである。 そのロックが強制解除されるということは、保護されていたデータが プログラマの意図していなかった矛盾した状態になってしまう危険がある。 こういった問題が起きないように安全にスレッドを止められるタイミングは、 そのスレッドが実行しているコード自身しか知らない。 安全のためには、スレッドは自分自身で止まるべきなのである。 他から止めたいスレッドには止めたいという要求を表すフラグを 用意しておき、止められるスレッド側で定期的にそのフラグを監視して、 要求があれば自分自身で止まるようにプログラムを書くことが推奨されている。 stop()メソッドは、使うべきではないという意味で、 非推奨(deprecated)メソッドとして指定されている。
stop()と同様に、suspend()も非推奨メソッドである。 こちらには、直接的にデッドロックを引き起こし得るという、 stop()とはまた違った危険がある。 モニタを獲得したままのスレッドが他者からsuspend()されてしまうと、 resume()で再開されるまでそのモニタは誰も獲得できなくなってしまう。 もし、resume()するはずのスレッドがそのモニタを待ってしまった場合、 デッドロックに陥る。
このように、Threadクラスのstop()、suspend()メソッドは スレッド絡みの問題を引き起こしやすいので、使用は避けた方がよい。
スレッドやロック絡みのバグは非常に発見しにくい。 潜在的にはバグがあっても、それがなかなか発現しないからである。 これまでは「運が悪いと」問題が起こると書いてきたが、本当は、 「運よく」問題が起きたと書くべきですらある。 発現してくれないことには問題に気づきようもない。 例えば、先ほどの銀行口座のデッドロック問題が実際に発現する確率は極めて低い、 ということは想像がつくだろう。 同じ2つの口座に対して、逆方向の送金が同時に微妙なタイミングで要求されて、 そこで初めて発現する。 単体テスト、結合テストといった通常の品質試験で発見できるような問題ではない。 へたをすると、何年かに一度、原因不明で無反応になるという困った ソフトウェアになりかねない。
発現させるためのタイミングが微妙であっても、 それを再現する方法があるならまだよい。 悪いことに、確実に再現する方法がない場合がほとんどなのである。 スレッド群は、複数のプロセッサ上で非同期に実行され得るし、 プロセッサがひとつであっても、いつ実行が別のスレッドに切り替わるかは 実行のたびごとに変化する。 プロセッサがひとつで、さらに、スレッド群のスケジュールが ノンプリエンプティブである場合、つまり、 スレッドが自分自身でThreadクラスのyield()メソッドを呼び出して実行を譲るまでは 切り替えが起きない環境であれば、 実行のたびに切り替わりのタイミングが変化することはだいぶ防げる。 例えば、Classic VMでGreen Threadsを使った場合である。 しかし、それでも問題が発現する微妙なタイミングを再現できるとは限らない。 仮に、切り替わりのタイミング、 つまりはスレッドのスケジューリングを一定にする方法があったとしよう。 しかしそれでも、そのスケジューリングで問題が発現するとは限らない。 実運用の環境で、スケジューリングが一定であることはまずないので、 切り替わりのタイミングが実行のたびに変化することは覚悟しておくべきである。
スレッドが関係する問題は再現が困難で発見しづらいため、 プログラムを書く前にきちんと知識を持って、 気をつけて設計、開発していくことが大切である。 問題が起きたら対応すればいいや、という心構えで開発していくと、 後で大きなつけを払うことになる。 同僚や以前の自分自身が、デッドロックの危険を抱えたリスト1のような コードを書いてしまった状況を想像して欲しい。 作ってしまった後でこういったバグを発見することは極めて困難であろう。
もちろん、研究者やツール開発者は、 プログラムの抱える問題をいかに自動的に的確に検出するか、 という努力を長年続けてきた。 例えば、単純なタイプミスであればコンパイラが警告してくれるし、 Javaは強く型付けされた(strongly typed)言語なので、 タイプミス以外の誤りもコンパイル時に多く検出できる。 しかし、スレッドやロックの問題に対して銀の弾丸は存在しない。 Javaコンパイラによるエラーチェックも無力である。
ソースコードをチェックして潜在的な問題の検出を支援する ツールを作ることはできるだろうし、現に存在もする。 例えば、プログラム中で共有データをアクセスしている箇所を ツールが抽出して提示してくれれば、レース状態の発見に役立つ。 明らかに複数のロックを獲得しているコードをデッドロックの恐れありとして 警告することもできよう。 しかしこういったツールはまったく普及していないし、 できることは飽くまで支援止まりである。 リスト1のデッドロックを自動的に検出できるツールはないだろう。 結局はプログラマの目による検査に頼らざるを得ない。
注意一秒ケガ一生である。
さて、デバッグである。 しつこく言うが、スレッドに関係するバグは再現が難しく、 デバッグは困難になりがちなので、予防が第一である。 一度作り込んでしまってからでは本当にどうにもならない場合もある。
何か問題を感じたときに、それがスレッドに関係した問題である兆候としては、 以下のものがある。
スレッド関係の問題とはすなわち、共有データとそのロックの問題である。 なので自然と、デバッグは共有データやモニタの監視が中心となる。 それだけではどうにもお手上げ、というときは、視点や気分を変えての 思考実験やプログラムの検査が有効なときもある。 プログラム中から共有データを操作している箇所を探して、 想像力を働かせてきちんとロックで保護できているか確認したり、 複数のモニタを獲得している箇所をピックアップして獲得順を検証するのである。
共有データの監視には、スレッド絡みだからといって特別なことは何もない。 普通のデバッグと同じように、System.out.println()を挿入したり デバッガを使うなどして怪しい変数の値を監視するのである。 この目的には、 Java 2 SDK付属デバッガjdbであれば、watch、unwatchコマンドが使えるだろうし、 IDE(統合開発環境)が提供するデバッグ機能が有効だろう。
共有データを監視するためには、 Java 2 SEの1.4から導入されるassertion機能も有効である。 この機能は、プログラマが期待する状態をassert文として プログラム中に記述しておくと、その期待が裏切られたときには (例外がthrowされて)実行が中断される、というものである。 それによってプログラマは、期待していた状態が崩れていて 何かまずいことが起きている、ということに気づけるのである。 この機能はレース状態の発見に非常に大きな力を発揮する。
Javaのassertion機能の重要な特徴は、ソースコードを再コンパイルすることなしに、 JVMを起動する際のコマンドラインオプションの指定によって 機能を有効にしたり無効にしたりできることである。 それでいて、まっとうなJITコンパイラ(例えばHotSpot VM)があれば、 機能を無効にした際には性能的なペナルティもないのである。 C言語でもassert()という関数が使える。 筆者はJITコンパイラのデバッグ中に、このassert()関数を使って レース状態を検出した経験がある。 ただし、C言語のassert()関数では、 機能の有効化、無効化のためには再コンパイルが必要であり、この点が Javaのassertion機能とは異なる。
デッドロックは、レース状態に比べればまだデバッグしやすい。 再現さえ出来たならば、その時点で、 どのスレッドがどのオブジェクトのモニタを獲得しているのかを調べれば よいのである。 例えば、Java 2 SDKに付属しているデバッガjdbにはthreadlocksという、 あるスレッドに関するモニタの情報を取得するためのコマンドがある。
> threads
Group system:
(java.lang.ref.Reference$ReferenceHandler)0x3 Reference Handler cond. waiti
(java.lang.ref.Finalizer$FinalizerThread)0x4 Finalizer cond. waiti
(java.lang.Thread)0x5 Signal Dispatcher running
(java.lang.Thread)0x6 CompileThread0 cond. waiti
Group main:
(java.lang.Thread)0xb Thread-0 waiting in
(java.lang.Thread)0xc Thread-1 waiting in
(java.lang.Thread)0xd Thread-2 running
> suspend
All threads suspended.
> threadlocks 0xb
Monitor information for thread Thread-0:
Owned monitor: instance of Foo(id=54)
Waiting for monitor: instance of Foo(id=55)
Thread-0[1] threadlocks 0xc
Monitor information for thread Thread-1:
Owned monitor: instance of Foo(id=55)
Waiting for monitor: instance of Foo(id=54)
図5: jdbのthreadlocksコマンド実行例
図5は、jdbを使ってデッドロックを検査している際の 入出力内容である。 まず、threadsコマンドでJVM上のスレッド一覧を取得している。 system、mainという2つのスレッドグループがあり、合計7つのスレッドを 含んでいることがわかる。 7レッドのうち3つは「cond. waiti」状態、2つは「waiting in」状態、 残り2つが「running」状態である。 他に「unknown」と表示されることもある。 日本語環境でJava 2 SDK 1.4を使っている場合は、 それぞれ「状況待機中」「モニタで待機中」「実行中」「不明」と表示される (表1)。 「cond. waiti」は、Objectクラスのwait()メソッドを呼んで待ち状態に入っていて、 notify()かnotifyAll()メソッドで起こされるのを待っている状態である。 「waiting in」は、モニタを獲得しようとして待たされていることを 表している。
表1: jdbで得られるスレッドの状態
英語 日本語 running 実行中 waiting in モニタで待機中 cond.waiti 状況待機中 unknown 不明
続いて、suspendコマンドで全スレッドを一時停止させた後、 threadlocksコマンドを使って、モニタ獲得待ちの2つのスレッドについて、 モニタ関連の情報を取得している。 出力を読むと、「Thread-0」という名前のスレッドは、 Fooクラスでidが54であるオブジェクトのモニタを獲得していて、 idが55であるオブジェクトのモニタを獲得しようとしていることが判る。 一方、「Thread-1」という名前のスレッドは、 idが55であるオブジェクトのモニタを獲得していて、 idが54であるオブジェクトのモニタを獲得しようとしている。 Thread-0とThread-1はお互いに相手が獲得しているモニタの解放を 待ち合って、デッドロックに陥っていることが判る(図6)。
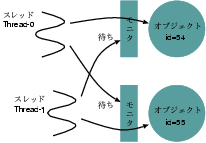
図6: デッドロックの様子
しかし、Sun社のHotSpot Client VMとHotSpot Server VMでは、 Java 2 SDK 1.4 Beta 2になってもthreadlocksコマンドがサポートされていない。 試みると次のメッセージが表示され、サポートされていないことが判る。 Linux用とWindows用のSDKで確認できた。
現状、jdbでthreadlocksコマンドを使いたければ、Classic VMを使うしかなさそうだ。 HotSpot VMではなくClassic VMを使うには、javaコマンドに-classicオプションを 指定すればよい。 自分がどのJVMを使っているのかを知るには、 javaコマンドに-versionオプションを指定すればよい(図7)。 しかし、Java 2 SDK 1.4からはClassic VMが付属してこない。 HotSpot VMのデバッガサポートがより強化されることを期待したい。> threadlocks 0x1 スレッド main のモニタ情報: ターゲット VM では、コマンド 'threadlocks' がサポートされていません
% java -version java version "1.4.0-beta2" Java(TM) 2 Runtime Environment, Standard Edition (build 1.4.0-beta2-b77) Java HotSpot(TM) Client VM (build 1.4.0-beta2-b77, mixed mode) % java -server -version java version "1.4.0-beta2" Java(TM) 2 Runtime Environment, Standard Edition (build 1.4.0-beta2-b77) Java HotSpot(TM) Server VM (build 1.4.0-beta2-b77, mixed mode) % java -classic -version java version "1.3.1" Java(TM) 2 Runtime Environment, Standard Edition (build Blackdown-1.3.1-FCS) Classic VM (build Blackdown-1.3.1-FCS, native threads, nojit)図7: java -versionの実行例
suspendコマンドでスレッドを一時停止させた後は、 where、whereiコマンドを使ってメソッド呼び出しの積み重ねを 調べたり、listコマンドでソースコード中の現在実行している部分を表示したり、 localsコマンドでローカル変数の値を調べたりできる。 jdbで使えるコマンドの一覧は、helpコマンドで見ることができる。 jdbは決して使いやすいツールではないので、作業の効率を求めるならば、 IDEが提供するデバッグ機能を使うべきだろう。
LinuxやFreeBSD、SolarisといったUNIX系のOS上でJava 2 SDK、JDKを 使っているならば、スレッドやモニタの状態を見るもっとお手軽な方法がある。 JVMのプロセスにQUITシグナルを送るのである。 HotSpot VMでの出力例が図8、 Classic VMでの出力例は図9である。 注意深く観察すると、jdbでは図5のように観察された デッドロックの様子(図6)がうかがえる。 たいていの環境(ターミナルエミュレータ、シェル)では、 「Ctrl」キーを押しながら「\」(バックスラッシュ)をタイプすることで、 フォアグラウンドジョブにQUITシグナルを送ることができる。 ちなみに、どういったキーを押すとどのシグナルを送れるのかは、 「stty -a」コマンドで知ることができる。 当然ながら、シグナル送信コマンドkillを使って 「kill -QUIT <プロセスID>」としてもよい。
…
"Thread-1" prio=5 tid=0x809df60 nid=0xdf2 waiting for monitor entry [0x4adb2000..0x4adb2834]
at Foo.run(Foo.java:16)
- waiting to lock <435e1dd0> (a Foo)
- locked <435e1de0> (a Foo)
at java.lang.Thread.run(Thread.java:484)
"Thread-0" prio=5 tid=0x809d370 nid=0xdf1 waiting for monitor entry [0x4abb2000..0x4abb2834]
at Foo.run(Foo.java:16)
- waiting to lock <435e1de0> (a Foo)
- locked <435e1dd0> (a Foo)
at java.lang.Thread.run(Thread.java:484)
…
図8: HotSpot VMにQUITシグナルを送った場合の出力例
Full thread dump Classic VM (Blackdown-1.3.1-FCS, green threads):
…
"Thread-1" (TID:0x40f5c310, sys_thread_t:0x819f358, state:MW) prio=5
at Foo.run(Foo.java:15)
…
"Thread-0" (TID:0x40f5c368, sys_thread_t:0x81980a8, state:MW) prio=5
at Foo.run(Foo.java:15)
…
Monitor Cache Dump:
Foo@40F5C378/40FDA448: owner "Thread-0" (0x81980a8) 1 entry
Waiting to enter:
"Thread-1" (0x819f358)
Foo@40F5C370/40FDA450: owner "Thread-1" (0x819f358) 1 entry
Waiting to enter:
"Thread-0" (0x81980a8)
…
図9: Classic VMにQUITシグナルを送った場合の出力例
ユーザインタフェースの応答性向上からマルチプロセッサ上での並列処理まで、 スレッドは近代的なプログラミング言語やソフトウェアには不可欠の概念、 技術となった。 Java言語や仮想マシンはスレッドありきという前提で設計されてきたので、 それを使うプログラマがスレッドを避けて通ることはまずできない。
Javaでは、java.lang.Threadクラスにはじまり、 モニタ、synchronizedという形で言語自身がスレッドをサポートしているため、 スレッドプログラミングは他の言語よりはずいぶんと容易で、 問題も起こしにくくなっている。
それでも、スレッドという概念が生来抱えているレース状態、デッドロックといった 問題を避けることは完全にプログラマの責任であり、残念ながらこれに近道はない。 マルチスレッドでどういった問題が起き得るのかをあらかじめきちんと理解して、 共有データの矛盾が起きないように慎重にモニタ操作を記述していくしかない。 また、デッドロックを避けるには、複数ロックの獲得方法をドキュメントに残し、 その規約を共同開発者全員で守っていく必要がある。
スレッド絡みのバグは、いったん作り込んでしまうと、 なかなか再現させることができなかったり、 ごく稀にだけ発現するような厄介なバグとなる。 問題が発現するずっと前に問題のあるコードが実行されているという、 原因の探求が困難な問題を起こすことも多い。 つまり、デバッグのコストが高く付きがちであり、予防が重要なのである。 この特集記事を機会に、読者のスレッドプログラミングへの理解が深まり、 日本の情報技術者の残業時間が減れば幸いである。