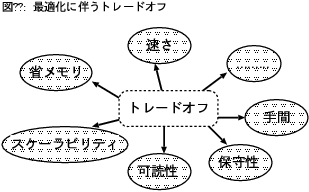
図1: 最適化に伴うトレードオフ
首藤一幸, "最適化の手引き", 月刊ジャバワールド 2000年 9月号, pp.58-75, IDGジャパン, 2000年 7月 24日
プログラムは、その書き方ひとつで性能が大きく変わる。 同じ目的を達成するプログラムであっても、書き方によって性能が数桁 異なる場合すらある。 「Javaは遅い」という評価が過去のものとなりつつある現在、 高い性能が要求されるアプリケーションがJava言語で開発される局面も増えてきた。 性能のよいプログラムを開発するためには、Javaに限らず、 アルゴリズム、コンピュータアーキテクチャ、コンパイラに関する理解が 重要なのはもちろん、他にも、 オブジェクト指向言語の実装、最適化手法、ガーベジコレクション、マルチスレッド など、Javaに関係する領域は非常に多岐にわたる。 加えて、Javaに固有の、仮想マシンやクラスライブラリに関する理解、 ノウハウも欠かせない。
ここでは、性能のよいプログラムの開発や性能改善、 つまり最適化について、採るべきアプローチなど、 プログラマなら知っておきたい事柄を述べる。 また、最適化という視点から見たJavaの特徴や、 Javaに固有の最適化手法にも言及する。
「最適化」とは何だろう? あらためて問われると返答に窮する方も多いのではないだろうか。 プログラムを速くすること、と答える方が多いかもしれない。 最適化手法の前に、まずは、そもそも「最適化」とは何なのかを 確認しておきたい。
「最適化する」に対応する英単語は「optimize」である。 この語の意味は、辞書によると次の通りである。
最高に活用する, できるだけ能率的に利用する。 (研究社 新英和中辞典より)つまり、プログラムの最適化とは、プログラムを実行する環境を できるだけ能率的に、最高に活用できるようにプログラムを書くこと、 改善することを指す。 ここでいう環境とは、もちろん、プロセッサ(CPU)から、 プログラムによってはハードディスクやネットワーク、その向こうにある 別のマシンまで含むかもしれない。 コードの書き方だけではなく、Java仮想マシン(JVM)起動時のパラメータや OS側の設定など、プログラムの外側での最適化が有効な局面も多い。
「最高に活用する」とはなんともおおざっぱで曖昧な表現だが、 「最適化」が指す範囲はそれくらい広い。 それゆえに、広範な知識や経験に基づいた、 環境や状況、目的に応じた対応が必要となる。
また、「最高に活用」「能率的に利用」とは、 単にプログラムの速さだけを指すわけではない。 例えば、手もとのプログラムを2倍速くする方法を考えついたとしよう。 しかしその方法は、それまでの3倍のメモリを消費する。 果たしてその方法を採用してよいかどうかは、 実行速度と省メモリのそれぞれがどのくらい重要なのかによって決まるだろう。
最適化の指標のうち代表的なものをいくつか挙げる。
図1: 最適化に伴うトレードオフ
ここに挙げた指標はそれぞれが独立しているわけではなく、 お互いが深く関係し合っている。 さきほどの例のように、2倍速くするためにメモリ消費量が3倍に なってしまうこともあるし、逆に、メモリ消費量を減らすことで 処理が速くなることも珍しくない。 このように複数の指標が同時に向上するのならよいが、 指標間の関係はトレードオフであることが多い。
筆者がある暗号方式をJava言語で実装していたときのことである。 あるとき、開発中のプログラムの処理性能を 2〜3割向上させる方法があることに気がついた。 ところがその方法を使うためには、暗号化、復号に先だってあらかじめ 128KBの表を作成しておく必要があった。 さらに、表のサイズを256KBとすることで最高の性能となることもわかった。 このプログラムが消費するメモリは、この表以外には数KBから十数KBだけだった。 さて、この手法は採用できるだろうか? 結論を言うと、当時の筆者らは採用した。 なぜなら、そのプログラムは、メモリ64MBという環境で 速さを評価するという目的でのみ使われることがわかっていたからである。 もしそのプログラムがメモリ量の制限がずっと厳しい環境で使われる予定だったなら、 採用できなかっただろう。
トレードオフが発生するのは、 このような複数の指標(性能とメモリ消費)の間だけではない。 多くの最適化が、プログラムの読みやすさ、つまり可読性を下げる。 可読性が下がれば、プログラムのメンテナンスのしやすさ、 つまり保守性も下がる。
例をひとつお目にかけよう。行列の乗算という数値計算を考える。 サイズがn × nの正方行列AとBを乗じて結果をCに格納する処理は こう書ける。
for (i = 0; i < n; i++) {
for (j = 0; j < n; j++) {
double sum = 0;
for (k = 0; k < n; k++) {
sum += A[i][k] * B[k][j];
}
C[i][j] = sum;
}
}
行列積が何であるかを知っていれば、このコードが何をしているかは
すぐに理解できるだろう。
このコードに対して、よく知られている最適化であるループ展開を施す。
最内ループについての4段のループ展開である。
for (i = 0; i < n; i++) {
for (j = 0; j < n; j++) {
double sum = 0;
for (k = 0; k + 3 < n; k += 4) {
sum += A[i][k] * B[k][j];
sum += A[i][k + 1] * B[k + 1][j];
sum += A[i][k + 2] * B[k + 2][j];
sum += A[i][k + 3] * B[k + 3][j];
}
for (; k < n; k++) {
sum += A[i][k] * B[k][j];
}
C[i][j] = sum;
}
}
これは、ループの終了条件が満たされているかどうかを判定する回数を減らすことで
高速化をはかろうという最適化である。
ループ展開を知らない人がこのコードを見ても、
何をするコードなのか、すぐには理解できないだろう。
つまり、可読性が低下したのである。
性能と可読性のどちらを優先させるべきかは、もちろん場合に依る。 ここでひとつ知っておくべきことは、可読性を低下させる このような最適化の多くは、プログラマが手で行わなくとも Just-In-Time(JIT)コンパイラなどの 処理系、実行系が行ってくれるということである。 そのため、可読性を落としてまで手で最適化するよりも 実行系にまかせた方が、たいていの場合は得策である。 また、もし現在は行ってくれないとしても、 ループ展開のように原理的には自動で行える最適化なら 将来の実行系は行ってくれるかもしれない。
最適化の際に考慮せねばならないトレードオフは他にもまだある。 プログラムの性質に関するトレードオフ以前に、 その最適化を施すか否かの時点で、 最適化にかかる手間とそれによって得られる利得の間にトレードオフが発生する。 次の場合を考えてみよう。 最適化前のプログラムは1回の実行に1ヵ月かかるところ、 ある最適化を施すとそれを1週間に短縮できるとする。 しかし、その最適化を施す作業は1ヵ月かかるとする。 そのプログラムが2回3回と使われるなら最適化の意味は大きいが、 もし1回しか実行されないならば最適化を施す意味はない。 最適化を行うことそれ自体が目的である場合は除いて、 手間に見合った利得があるかどうかを考えるべきである。
最適化の結果はプログラマの質を如実に反映してしまう。 プログラマには、コンピュータやアルゴリズム、 最適化への取り組み方についての相応の見識が求められる。 ここでは、最適化にはどんな知識、理解が求められるかを述べていく。
まずは、いくつかの例を通じて、 プログラマに何が求められるのかを見ていこう。
配列に格納されている値の中から最大値と最小値を探すという処理を考える。 素直に書くとリスト1のようになるだろう。 ある要素を最大値候補(max)と比較し、より大きければ新しい最大値候補とする。 次に、最小値候補(min)と比較し、より小さければ新たな最小値候補とする。 この方法は誰でも思いつく。
int a[] = new int[SIZE];
int max, min;
int i;
……
max = min = a[0];
for (i = 1; i < SIZE; i++) {
if (a[i] > max)
max = a[i];
else if (a[i] < min)
min = a[i];
}
リスト1: 最大値と最小値の探索 --- 素直に書いたもの
このアルゴリズムでは、大小比較の回数は、 最悪の場合、配列長(SIZE)の倍である。 elseによって若干の比較をさぼれるが、ほとんど期待できない。 ところが、リスト2のように書くことで、 大小比較の回数を約3/4に削減できる。 比較回数が減る分、処理にかかる時間は短くなるだろう。
int a0 = a[0], a1 = a[1];
if (a0 > a1) {
max = a0; min = a1;
}
else {
max = a1; min = a0;
}
for (i = 2 - (SIZE & 1); i < SIZE; i += 2) {
a0 = a[i];
a1 = a[i + 1];
if (a0 > a1) {
if (a0 > max)
max = a0;
if (a1 < min)
min = a1;
}
else {
if (a0 < min)
min = a0;
if (a1 > max)
max = a1;
}
}
リスト2: 最大値と最小値の探索 --- 工夫したもの
仕掛けはこうである。配列を1要素ずつ見ていくのではなく2要素ずつ見ていく。 2要素を取り出して比較する。 2要素のうち大きい方を最大値候補(max)と比較し、 小さい方を最小値候補と比較する。 最初のアルゴリズムでは、配列の1要素あたりおよそ2回の大小比較をしていたが、 2つめのアルゴリズムでは、2要素あたり3回の比較で済む。
int型の1次元配列a[]の要素すべての値を1/2にする。 値を1/2にする方法として、2で割る、1/2を乗じる、の他に、 1ビットだけ算術右シフトするという方法もある。 それぞれの処理は次のように書ける。
除算(1): a[i] /= 2; 除算(2): a[i] /= 2.0; 乗算: a[i] *= 0.5; シフト: a[i] >>>= 1;
配列長を1000万として、これらを筆者の手もとの環境 (Pentium II/333 MHz, Linux, IBM JDK 1.3)で実行した際にかかる時間は 次の通りである。
筆者の環境では算術シフトを使った方法が最も速い。 この実行時間の差がどこからくるのかを推定、調査する能力が 最適化に役立つことは疑いない。 たいていの場合、シフトは乗除算より軽い処理であり、除算のように 実行時間がオペランド(計算対象の値)に依存するようなこともない。
除算(1): 600 除算(2): 1020 乗算: 1030 シフト: 540 (ミリ秒)
では、乗算はたいてい除算より軽いからといって 除算よりは乗算を使えばよいかといえば、それだけでは済まない。 乗算より除算(1)の方が速いという結果が出ている。 除算(1)ではint型の整数で割っているので整数どうしの除算が行われる。 それに対して、除算(2)と乗算では右辺がdouble型なので、 int型である左辺のa[i]は演算の前にdouble型に変換される。 Java言語の仕様が、変換せよ、と定めているのである。 また、演算の後で結果をa[i]に格納する際には、 結果をdouble型からint型に変換せねばならない。 除算(2)と乗算の方法にはこの変換のオーバヘッドがある。
しかし実を言うと、JVMとJITコンパイラがブラックボックスであるため、 プロセッサが本当に上に書いたような処理を行っているのかどうかはわからない。 JITコンパイラが浮動小数点演算を整数演算に置き換えているかもしれない。 しかし、除算(1)と(2)の実行時間に大きな差が見られたことと、 そのような置き換えには慎重な検査が要るわりには有効な局面が少ないことから、 上に書いた言語仕様通りの変換処理が行われているものと思われる。
大きな配列の内容をファイルに保存する処理を考える。 次のコードは、何も考えずに書き下した場合を想定したものである。
int[] a = new int[SIZE];
……
OutputStream out =
new FileOutputStream("ファイル名");
DataOutputStream dout =
new DataOutputStream(out);
for (int i = 0; i < SIZE; i++) {
dout.writeInt(a[i]);
}
配列長(SIZE)を100万として、このプログラムを 筆者の手もとで実行すると27秒かかる。
しかし、new FileOutputStream(…)の次の行に
という1行を加えると、とたんに実行時間は1.01秒となった。 およそ1/27になった計算である。 元のプログラムでは writeInt(…)の呼び出しごとにOSに対して書き込み要求が起きていた。 それが、BufferedOutputStreamのインスタンスとして バッファを用意したことで、ある程度の書き込みデータがたまった時点ではじめて OSに書き込みを要求するようになったためである。 OSへの要求という時間のかかる、重い処理の回数が減ったことで、 実行時間が短縮されたわけである。out = new BufferedOutputStream(out);
これらの例は、最適化の際にプログラマに求められるものを示唆している。
Javaに固有の事柄も多いながら、これらのほとんどは どんなコンピュータプログラムの最適化に通用する。
例1: アルゴリズム 例2 コンピュータアーキテクチャ(プロセッサ), Java言語, 処理系(JITコンパイラ) 例3 システムソフトウェア(OS), クラスライブラリ
アルゴリズムとデータ構造、特に計算量に対する理解は、 プログラミング言語の入門書には載っていないにも関わらず、 どんなプログラマにも必須である。 あるアルゴリズムでデータ量nが3倍、4倍となったときに 実行時間が32=9倍、42=16倍となる場合、 そのアルゴリズムのオーダはn2であると言い、O(n2)と書く。 このオーダの違いは、実行時間に決定的な差をもたらす。 例えば、同じ結果が得られるアルゴリズムAとBがあり、それぞれ O(n)、O(n2)だったとしよう。 データ量が1000倍になったとき、Aの実行時間は1000倍で済むが、 Bの実行時間は10002=100万倍となってしまう。
データを指定された順に並び替える操作であるソートに、 オーダの違ういくつもの方法があることは有名である。 単純なバブルソート、挿入ソート、選択ソートはO(n2)だが、 マージソート、クイックソートなどはO(n log n)と、より効率が良い。 nを増やした場合の伸びを比べると、n log nの方がn2より小さいのである。
オーダの低いアルゴリズムがベターではあるが、 もちろん状況に応じた選択をすべきである。 目的の処理が、データの個数が100の場合に O(n2)のアルゴリズムで1秒で済むところ、 O(n)のアルゴリズムでは10秒かかるとする。 データ数が10倍以上になれば実行時間の逆転が起こるわけだが、 もしデータ数がこれ以上増えないことがわかりきっているなら、 何もO(n)のアルゴリズムを採用することもない。 コンピュータアーキテクチャ、つまりコンピュータの仕組みについての理解は、 Javaに限らず、プログラムがコンピュータ上で実行されるものである以上、 とても重要である。 高速化の観点からは特に、メモリ階層とプロセッサ(CPU)に対する理解が ポイントとなる。
近年のコンピュータでは、プロセッサデータ処理速度と メインメモリのデータ供給速度の差が開く一方なので、 プロセッサのレジスタとメモリの間にキャッシュメモリを設けることが普通である。 記憶装置はレジスタから、1次キャッシュ、…、メモリ、ディスクと階層をなしている。 プロセッサに近いほどデータ供給速度が速いのだが、逆に容量は限られてくる。 メモリ上のデータすべてをキャッシュに載せておくことはできないので、 最近アクセスされた近辺のデータを載せておくという手法がよく用いられる。 これは、最近使われた近辺のデータはまたすぐに使われる可能性が高いという 経験則に基づいた方法である。
このような理由から、メモリ上で連続しているデータの順次アクセスは 速いが、メモリ上に分散しているデータをばらばらとアクセスすると 時間がかかるようになっている。 例えば、筆者の手もとで、長さ400万のint型の配列をある値で初期化する場合、 配列の先頭から順に初期化していくと、170ミリ秒で済むところ、 とびとびに初期化すると倍の360ミリ秒かかってしまう。 このように、ディスクよりはメモリ、メモリよりはキャッシュに載っている データを使えるように考えて、なるべく局所的にメモリをアクセスすることが 有効である。
プロセッサについては、例2のように、 あるJavaプログラムに対してどんな命令が実行されるのかを推測できると、 それが最適化の指針となる。 もうひとつ知っておくとよいのは、 最近のプロセッサでは条件分岐のコストが高いということである。 正確に言うと、プロセッサによる分岐先予測が外れた際のペナルティが大きい。 例えば、Pentium II/IIIの元となっているPentium Proでは、 予測が当たると1クロックでジャンプできるが、 もしはずれると、9〜26クロックものペナルティが発生する。 1万回繰り返されるループなら9999回は予測が当たるのでまず問題にはならないが、 switch文で、周期性もなく毎回さまざまに分岐する場合などは、 分岐のたびに大きなペナルティが発生することになるだろう。
例3で示したように、OSといったシステムソフトウェアの理解も役に立つ。 また、Javaプログラムがプロセッサによって実行されるまでには、 Javaコンパイラ、JITコンパイラ、Ahead-of-Time(AOT)コンパイラなど さまざまなコンパイラが関係するので、コンパイラに関する理解も 最適化の大きな助けとなる。 Javaコンパイラはさまざまな制約から大幅な最適化はしないのだが、 JITコンパイラ、AOTコンパイラは、これまで他の言語で培われてきた 各種の最適化を行う。 したがって、それらの最適化手法を知ることで、 プロセッサが何を実行するのかを推測できたり、 コンパイラが最適化しやすいコードを書く指針がわかるようになる。 一例を挙げると、メソッドをpublicよりはprivateやfinal にすることで、JITコンパイラがそのメソッドの呼び出しを高速化できる 可能性が高まる、といったことがわかってくる。
ここまで述べてきたことはJava以外のプログラミング一般に通じる事柄である。 もちろん他に、Javaに固有で有用な知識もたくさんある。 バイトコード、実行時(JIT)コンパイラとインタプリタ、ガーベジコレクション(GC)、 例外、マルチスレッド、同期、また、標準クラスライブラリに対する 理解も役立つ。 これらを意識した、Javaに特化した最適化手法については後ほど述べる。
プログラムを速くしたい。メモリの消費量を少なくしたい。 さて、何をすべきだろうか。 やみくもにプログラムを書き換えても仕方がない。
まずは計測である。 処理にかかっている時間や消費メモリ量を把握しないことには、 最適化の効果を知ることすらできない。 C言語でのgettimeofday()に相当するメソッドとして、 Java言語にはjava.lang.Systemクラスの currentTimeMillis()メソッドがあり、 現在時刻をミリ秒単位で得られる。これを使って、
long t0, t1, elapsedTime;
t0 = System.currentTimeMillis();
時間を計測したい処理
t1 = System.currentTimeMillis();
elapsedTime = t1 - t0;
とすることで、elapsedTimeに、処理にかかった時間を得ることができる。
時間を計測する方法にはさまざまあり、例えばUNIX系統のシステムであれば
timeコマンドを使うという手もあるだろう。
プログラムの実行時間についてはよく、 実行時間の90%がプログラムの10%の部分に費される、 と言われる(図2)。 この割合はプログラムの性質によって様々だが、 どんなプログラムでもその部分ごとに、 実行される頻度や時間が異なるのは確かである。 この、頻繁に実行される10%の部分を指してホットスポット(hot spot)と言う。 SunのHotSpot VMの名前の由来である。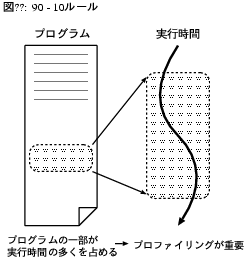
図2: 90 - 10 ルール
プログラムを高速化したい場合、 あまり実行されない部分に力を注いでも効果は薄い。 実行時間の90%を占める部分を放っておいていくら高速化を頑張っても、 たとえ残り10%の実行時間を0にできたとしても1割しか速くならない。 しかし、実行時間の90%を占める部分を倍速くできたなら、 総実行時間は45%短縮され、およそ倍速くなる。 やみくもに取り組んでも速くならない理由はここにある。 このように、高速化に取り組む際は、 まずは実行時間の長い部分を見つけることが肝要である。
どの部分が頻繁に実行されているのかなどのプログラムの挙動を調べることを プロファイリングという。 C言語の場合、たいていはプロファイリングに対応した方法で コンパイルしておく必要があるが、JavaでJVMを使う場合は特別な準備は要らない。 普通にJavaコンパイラでクラスファイルを作っておけばよい。
実行頻度は、メソッドごとの実行時間として得られるのが一般的である。 開発環境を使うと、グラフなどを用いて所要時間の偏りを わかりやすく示してくれることが多いが、 JDKだけでもプロファイリングはできる。 JDK 1.2以降の場合
JDK 1.1の場合> java -Xrunhprof:cpu=times,file=log.txt クラス名
とすることで、ファイルlog.txtにプロファイリングの結果が残る。 ファイル名は、指定しなかった場合java.hprof.txtとなる。 また、appletviewerでも次のようにすることで、プロファイリングはできる。> java -prof:log.txt クラス名
> appletviewer -J-Xrunhprof:...
プロファイリング結果を記録したファイルの内容は次のようになっている。
CPU TIME (ms) BEGIN (total = 1020) Thu Jun 1 10:08:00 2000
rank self accum count trace method
1 31.37% 31.37% 4950 28 Linpack.daxpy
2 3.92% 35.29% 2 10 Linpack.matgen
3 3.92% 39.22% 2872 45 sun/io/ByteToCharSingleByte.getUnicode
4 2.94% 42.16% 5808 32 java/lang/String.charAt
……
10 1.96% 54.90% 5049 22 Linpack.abs
……
この例では、Linpackクラスのdaxpy()メソッドが4950回呼ばれて、
総実行時間のおよそ3割を占めていることがわかる。
もしdaxpy()の処理時間を短縮できれば、全体の高速化に大きく寄与するだろう。
また、StringクラスのcharAt()メソッドと、 Linpackクラスのabs()メソッドの呼び出し回数が多いこともわかる。 これらを呼び出すためのオーバヘッドを減らせれば高速化が期待できる。 もし性能が厳しく問われるなら、 JITコンパイラによるインライン展開という最適化を促進するために これらのメソッドをfinalやprivateにするという手がある。 (実はabs()もStringクラスもすでにfinalである。) 性能に対する要求がより厳しいなら、呼び出し側のソースコード中に abs()やcharAt()の処理内容を書いてしまうことも検討する価値はある。 とはいえ、たいていは、 このようなインライン展開はJIT、AOTコンパイラに任せるのが賢明である。
JDK 1.2以降では、メソッドごとの実行時間だけではなくて、
ヒープ上にどれだけのオブジェクトが作られたか、や、
モニタ(ロック)に関する挙動を調べることもできる。
詳しくは
Javaプログラムもコンピュータで実行される以上、
最適化に必要な多くの知識や理解は他の言語と共通のものである。
しかし、Javaは、Javaの適用範囲でこれまで使われてきた他の言語とは
異なる性質も持っている。
ここでは、主にPCより大きい環境を想定して、
最適化に関するJavaの特徴を述べていく。
最適化についてCやC++、FORTRAN、COBOLなどと比較した場合、
Javaは次の特徴を持っている。
Javaでは、プログラムの書き方と性能の対応関係が、
Cなどよりさらに安定していない(図3)。
困ったことに、どのように書けば速くなるのか、または遅くなるのかを予測しにくい。
理由としては、
Cよりも踏まえるべき知識が多いためにまだ熟練者が少なく、
ノウハウが浸透していないせいもあるかもしれない。
しかし理由はそれだけでもない。
JITコンパイラの有無やAOTコンパイラの使用などさまざまな実行方法があって、
実行方法によって同じプログラムの性能が変わる。
JVM、JITコンパイラの種類によっても性能は変わる。
そして、ある実行方法では速かった書き方が別の実行方法では遅いということが
当たり前に起こってしまうのである。
例を挙げよう。配列をコピーする処理を考える。
byte型の配列src[]の中身をdst[]にコピーする。
素直に書くと次のコードになるだろう。終了条件を添字の値で判断している。
以上、JITコンパイラの有無やJVM、JITの種類によって
性能の優劣が入れ替わる例を見てきた。
さて、この性能差、また、逆転はどうして起きたのだろうか。
それを詳細に調べるには、与えられたプログラムに対して
プロセッサが何を実行したのかを知る必要がある。
つまり、JVMが何をしたのか、JITコンパイラがどんなコードを生成したのか、である。
残念ながら、一般にはJITコンパイル結果を見ることはできない
(図4)。
javapコマンドなどでクラスファイルを逆アセンブルして見ることができるのは
バイトコード命令までで、プロセッサが実際に何を実行したのかは
わからないのである。
この点が、コンパイル結果を逆アセンブルしてプロセッサの命令列を
直接見ることができるCやC++、FORTRANとは異なるところである。
もっとも、JITコンパイラのソースコードが手に入るなら
どんなコードを生成するのかを知ることもできようし、
JITコンパイラの内部を記した記事や論文もあるにはあるので、
手がかりは皆無ではない。
また、AOTコンパイラを使う場合は実行前にそのプロセッサ用のコードが得られるので、
コンパイラのライセンスが許すなら、逆アセンブルしての調査が可能である。
挙動の調べやすさという点では、インタプリタやそれを含むJVMについても
状況は芳しくない。現在手に入るほとんどのJVMはソースコードが手に入らない。
JapharやKaffeといったソースコードから公開されているJVMもあるし、
Sunもサンプル実装であるclassic VMや以前のHotSpot VM(1.0.1)については
ソースコードを公開している。
しかし、JVMの性能でトップランナーであるIBMやSunなどは
内部で大幅にJVMを改良しており、そのソースコードは公開されていない。
残念ながら、ブラックボックスが多いのである。
また、適応的コンパイルや同期コストの削減手法など、
いま盛んに研究されているテクニックがJVMやJITコンパイラに
採り入れられてきているために、
プログラムの書き方と性能の対応関係は今なお変化し続けている
という事情もある。
このように、Javaでは、頑張ってカリカリ調整して速くしたとしても、
その最適化が他の実行方法や将来の環境でどのくらい有効なのかは
かなり不透明である。
速くしたつもりが他の環境で遅くなることはあるし、
その最適化も3ヵ月後にはJITコンパイラが行ってくれるかもしれない。
Javaでは、可読性などを犠牲にしてまでの極度の最適化は、
プログラマの手で行っても仕方がないことが多いのである。
もちろん、それでも特定の実行環境、ソフトウェア上で
最大限の性能を発揮するコードを書くことが必要な局面はあるだろう。
その場合は、その環境をよく知り、実際の環境でまめに効果を測定しながら
最適化をすすめていくことが大切である。
インスタンスの生成は重い処理である。
Javaでは配列もインスタンスなので、配列の生成も同様である。
重い、軽いというのは相対的にしか言えないので例を挙げると、
筆者の環境で100万回の整数除算が90ミリ秒で済むのに対し、
同じ回数のインスタンス生成(java.lang.Objectクラス)には890ミリ秒かかる。
また、生成それ自体が重いだけではなくGCへの影響もある。
インスタンスを多量に生成すると当然GCが起こりやすくなる。
例えば、プログラムがGUI中心でアイドル時間が充分にあれば、
プログラムがそれ自身の処理をしていない間にGCが起こって
使用感には影響がないかもしれない。
しかしアイドル時間がない種類のプログラムだと、
GCがプログラム本体の処理時間を奪うことになる。
このように、インスタンスの生成量は消費メモリ量だけではなく、
プログラムの性能にも影響を与え得る。
また、悪いことに、インスタンスの生成はJITコンパイラで高速化されにくい。
インスタンス生成はJVM自体がはじめから持っている機能なので、
たいていのJVMではJITコンパイルの対象とはならないからである。
JITコンパイラが生成自体を省いてくれたり、
インスタンスが本当に必要になるまで生成を遅らせてくれる場合もあるにはあるが、
これらが行われる場合は非常に限られるのであまり期待はできない。
そのため、プログラマが手でインスタンス生成回数を減らすことは
有効な最適化である。アプローチはさまざまである。
例えば、あまりおすすめはできないものの、
プログラムが1プロセッサで良い性能を発揮しさえすればよいなら
このような方法もある。
メソッド呼び出しのたびにインスタンス(buffer[])を生成している
次のコードを
生成したインスタンスを使い回すことで生成を回避する手法として、
オブジェクトプールというものがよく知られている。
この手法は、java.lang.Threadクラス、つまりスレッドに対して
非常によく用いられ、特にスレッドプールと呼ばれている。
よく用いられるのは、
スレッドの生成コストが他の多くのクラスよりもさらに大きいからである。
いわゆるサーバ側プログラムでは、ネットワーク経由のリクエストに対して
スレッドを割り当てていくことが多いので、
スレッドプールは必須のテクニックとなっている。
どんな処理でも受け付けられる、汎用の、効率よいスレッドプールを
書くことは、それ自体が興味深い演習問題である。
ぜひ一度は挑戦して欲しい。
性能面で鍵となるのは、いつ、どの時点で下位のスレッドが作られるのか、である。
Threadクラスのインスタンスは、自身に対応する、より下位に位置する、
CライブラリまたはOSレベルのスレッドを持つ。
そういった下位のスレッドを生成する処理がまた重いので、
性能を求めるなら下位のスレッドが生成された状態までもっていってから
プールに貯めておくべきである。
注意して欲しいのは、Threadのインスタンスを生成しただけでは、
下位のスレッドが生成されたとは限らないということである。
下位のスレッドはstart()が呼ばれた時点で生成されれば間に合うので、
それまで下位のスレッドは生成されていないかもしれない。
プールに貯める前に、スレッドに対してstart()まで呼んでおくとよい。
Javaでは、配列の要素へのアクセスがCと比べて重い処理となっている。
理由はいくつかある。
まず、配列もインスタンスなのでアクセスの際はnullかそうでないかの
チェックが必要となる。
もしnullなら例外を発生させねばならない。
このnullチェックは、環境によってはOSの機能で行えて
オーバヘッドとならない場合も多い。
また、Javaではご存知の通り添字の範囲チェックも行われる。
添字が0未満、または配列長以上だった場合は例外が発生する。
これらのチェックはどちらも、
JITコンパイラがデータフロー解析やloop versioningによって
除去してくれることがある。
境界チェックを一切行わない、という設定を受け付ける
JITやAOTコンパイラもあるかもしれない。
それはすでにJVMの仕様を逸脱しているし、
範囲外アクセスによってクラッシュするかもしれないが。
配列のアクセスコストを減らすためにプログラマができることは
そう多くはないが、指針はある。
まず、チェックが不要であることをJIT、AOTコンパイラが読み切れるような
コードを書くことである。
例えば、次のコード中のarray[i]で、iが
配列の境界を越えることがあり得るだろうか?
この例はやさしくはないが、人間にとってわかりやすくて明らかに
最適化できそうなコードは、コンパイラにとっても解析が容易であることが多い。
わかりやすいコードを書くことがコンパイラを助けることとなる。
プログラマにできることは他にもあるにはある。
例えば、配列の長さがたかが知れている場合は、そもそも配列にせずに
スカラ(配列でない)変数にするという方法もある。
つまり、a[3]の代わりにa0,a1,a2と3つのスカラ変数を使うのである。
もっとも、可読性を損なってまでこの方法を採用すべきかは
慎重に検討せねばなるまい。
多次元配列はアクセスも重い。
また、Cでは添字を元にアクセス先のアドレスを計算してから
要素にアクセスできるが、
Javaでは最悪の場合、1次元配列へのアクセスを次元数の回数繰り返すことになる。
その場合、メモリ上で離れた地点をとびとびにアクセスすることで
キャッシュミスを起こしかねない上に、
境界チェックなど配列アクセスのオーバヘッドが次元数倍になる。
もっとも、同じ要素への繰り返しのアクセスや、隣接する要素への順次アクセス
など、JIT、AOTコンパイラがオーバヘッドを削減できる場合もある。
プログラマができることとして、次元数の削減という方法がある。
例えば、a[100][2][5]という配列があった場合に、
代わりに、要素数は変えずにa[100][10]という配列を用意する。
そして、a[i][j][k]とアクセスしていたところ、
a[i][5*j + k]とアクセスするのである。
もっと極端に、a[1000]をa[10*i + 5*j + k]とアクセスしてもよい。
この方法の効果を調べた。
行列積で、2次元配列を1次元配列に書き換えて、実行時間の違いを見る。
元のコードはさきほどと同じものである。
AとBを乗じた結果をCに格納するという処理である。
多次元配列のアクセスが重いというこの問題は、
Javaを数値計算、高性能計算に使おうというコミュニティである
Java Grande Forumで議論されている。
結果、多次元配列の新しいAPI(例: doubleArray2Dクラス)と、そのAPI中のクラスと
対応付けられるa[i,j]という形式の新しい文法が考えられた。
それぞれすでにJava Specification Request(JSR)として提案され、
仕様策定手続きJava Community Process(JCP)に沿って標準化の作業が行われている。
ただし、もし仮に採用されるとしても、
2001年に予定されているJDK 1.4(コード名J2SE Merlin)にはもう間に合わないので当分先の話である。
Javaの変数にはいくつかの種類がある。
Java仮想マシンの仕様書によると7種類あり、すなわち、
クラス変数、インスタンス変数、配列の要素、メソッド引数、
コンストラクタ引数、例外ハンドラ引数、ローカル変数である。
実際のところ、JVM内では
メソッド引数、コンストラクタ引数、例外ハンドラ引数は
ローカル変数の一種となっているので、実際は
クラス変数、インスタンス変数、ローカル変数、配列の要素の4種と考えられる。
変数アクセスのためのバイトコード命令も、これら4種に対応するものが
それぞれ用意されている。例えば、クラス変数の読み出しであれば
getstatic命令、といった具合である。
変数の種類が違えば、読み書きのコストが違ってくる。
どのくらいの違うものか調べるために実験を行った。
次のコードで、
繰り返し回数nを1億とし、
筆者の環境(Pentium II/333 MHz, Linux)で、IBM JDK 1.3とSun JDK 1.3を使って
の結果を表3に示す。
すべての場合でローカル変数が最も速かった。
インスタンス変数とクラス変数を比較すると、
Sunのインタプリタを除いてインスタンス変数の方が良い結果を示した。
インスタンス変数とクラス変数のどちらへのアクセスが重いかは
実行環境やコードに依るので、一概には判断できない。
プログラマとしては、ローカル変数は比較的アクセスコストが低い、
ということを知っておけばよい。
すると、高速化の方法としては例えば、
頻繁にアクセスする変数はローカル変数にしておいたり、
インスタンス、クラス変数をいったんローカル変数に代入してから
頻繁にアクセスする、といった方法が考えられる。
しかしやはり、こういった書き換えはコードの理解しやすさ、可読性を
損ねることが多いし、
JITコンパイラがインスタンス変数、クラス変数をローカル変数として扱うといった
最適化を行ってくれる場合もある。
損得をよく考えて採用すべきであろう。
では、なぜ、こういったアクセスコストの違いが出てくるのか?
アクセスコストの観点から3種の変数を比較する。
インスタンス変数では、アクセスの際に
対象インスタンスがnullかどうかのチェックが必要となる。
もっともnullチェックにOSの機能を使える場合はこれはオーバヘッドとは
ならないし、JIT、AOTコンパイラがチェックを省いてくれることもある。
また、1.2.2までのWindows用JDKのようにclassic VMというJVMを使っている場合は、
メモリ(ハンドル)の内容を見てそこに書いてあるアドレスを参照するという
間接参照が行われ、オーバヘッドとなる。
クラス変数へのアクセスではnullチェックは不要である。
また、インスタンス変数とは違い、
JITコンパイルの時点で変数の格納先アドレスを確定できるので、
実行時にアドレス計算が要らないという長所はある。
もっとも、アドレス計算はもともとたいしたオーバヘッドではない。
逆に短所としては、クラス変数のアクセスが、
ごく稀にそのクラスの初期化を引き起こし得るという点が挙げられる(図6)。
クラスの初期化とは、static initializer (static {…})の実行や
クラス変数の初期化を指す。
Java仮想マシン仕様はクラスの初期化が行われるタイミングを厳密に定めていて、
そのうちのひとつがクラス変数へのアクセスなのである。
ロード後1度だけ行われるべきである初期化をどのように
効率よく実装するかは、インタプリタ、JIT、AOTコンパイラを問わず、
Javaの実行系共通の課題である。
クラス変数へのアクセスのたびに初期化済みかどうかをチェックして…という方法は
いかにも無駄である。
その実装方法によっては、2度目以降のアクセスにも
ある程度のオーバヘッドが課せられてしまうこととなる。
最後にローカル変数である。
ローカル変数には、上で述べた、
インスタンス変数、クラス変数のようなオーバヘッドがない。
良い点はもうひとつある。JIT、AOTコンパイラの立場から見ると、
Java言語、仮想マシンの仕様を侵さずに
安全にレジスタに割り付けられるのは、ローカル変数だけである。
詳細な理屈は省くが、クラス変数とインスタンス変数は
自スレッドだけでなく他のスレッドからも
アクセスされる恐れがあるため、レジスタに割り付けることが難しい。
インスタンス変数もローカル変数と同様にレジスタに割り付けようという
最適化を行うコンパイラもあるが、常にうまくいくとは限らない。
複数のスレッドから共有される可能性があるという
クラス変数、インスタンス変数の性質は、
JIT、AOTコンパイラによるその他の最適化も妨げかねない(図7)。
配列アクセスに関する説明の際に述べたように、
ローカル変数でなかったばかりに省けるはずの配列境界チェックを
省けなくなることもあり得る。
他にも、同期、ロックを省くチャンスが減ることもあり得る。
次のコードを見て欲しい。
ところが、変数vecがローカル変数でなかったらどうだろう。
vecが指すインスタンスを他のスレッドが参照してしまう可能性が出てくる。
すると、ロックは無駄とはならないので、
コンパイラとしてはロックを省くわけにはいかなくなる。
このように、変数の種類はコンパイラによる最適化にさまざまな影響を与え得る。
プログラマとしては、JIT、AOTコンパイラはローカル変数について最適化を施しやすい
と覚えておいて欲しい。
同期、つまりインスタンスに対するロックの取得、解放処理は比較的重い処理である
(図8)。
高性能を目標としたJVM、コンパイラの開発者はみな、
同期処理を軽くしよう、可能なら削除しようと努力している。
プログラマができることは、
synchronizedブロックへの突入と
synchronizedメソッドの呼び出し回数、
つまり同期の回数を最小限にすることである。
とはいえ、複数スレッド間の排他制御がどうしても必要な局面は残る。
それでもさらに同期回数を減らしたければ、
複数の同期を1度にまとめるという方法もある。
次のように何度もロックを取得、解放する代わりに、
同期に関する問題は、プログラマが書くコード上に存在するだけではない。
Javaの標準クラスライブラリがすでに多量のsynchronizedを
含んでしまっている。
例としてjava.util.Vectorクラスを見よう。
JDK 1.3では、45あるpublicメソッドのうち、
実に30ものメソッドがsynchronizedメソッドとなっている。
プログラマが排他について無頓着でも、複数のスレッドが走った際に
問題が起きないように、最大限安全なように書かれているのである。
それこそ、ひとつのスレッドしか走らないプログラムでは、これらの
synchronized指定はまったくの無駄でしかない。
プログラマとしては、このように同期が無駄な場合はJIT、AOTコンパイラが
削除してくれることを期待したい。
そのためにできることは、変数の種類についての説明の際に述べたように、
無駄だということを
コンパイラが解析しやすいコードを書くことくらいである。
同期のコストをぎりぎりまで切り詰めたい場合は、標準ライブラリ中のクラスを
そのまま使わずに代替クラスを自分で用意するという手段もある。
例えば、Vector.javaを元にsynchronizedの記述を削除した
代替クラスを用意してそれを使うのである。
この場合、当然であるが、複数スレッドからアクセスした場合に
問題が起きないことを保証するのはプログラマの責任となる。
必要なら排他制御は自分で行わなければならない。
メソッドのアクセス修飾子(access modifier)である
public、protected、privateやfinal、static宣言は、
メソッドの呼び出しコストに影響を与える。
どのくらい違うものか見てみよう。
次のメソッドを3千万回呼び出し、所要時間を計測した。
インスタンスメソッド(static以外)では、どの環境でも
privateメソッドの呼び出しが速い。
また、finalを付けることで多くの環境で速くなっている。
クラスメソッド(static)はJITコンパイラではprivateメソッドとほぼ同じ結果で、
インタプリタではprivateよりもさらに若干速いという結果となった。
この結果から導ける指針は、アクセス修飾子は極力狭く、privateに近くし、
可能ならfinalを付けるということである。
また、インスタンスメソッドをクラスメソッドに変更してしまうという
高速化も考えられる。
しかしこれは設計の問題でもあるので慎重に検討すべきであろう。
なぜ、privateでないインスタンスメソッド(public, protected)の
呼び出しコストが高いのかは、
オーバライドと動的呼び出し(virtual invocation, dynamic dispatch)に関係がある。
例えば、クラスAがあったとして、
A型の変数に対してインスタンスメソッドfoo()を呼び出すというコードを
書いたとする。
もしAのサブクラスがfoo()をオーバライドしていた場合、
その呼び出しで実際に呼び出されるメソッドは
対象インスタンスのクラスによって決まる。
そのクラスは実行時にならないとわからないので、
実行時に、呼び出すべきメソッドを決定するためのオーバヘッドがある。
例えば、単純な実装では、実行時にクラスの階層を辿って調べたり表をひいたり
するので、その処理がオーバヘッドとなる。
それに対して、privateメソッドはオーバライドされようがないので、
プログラマがコードを書いた時点でどのメソッドが呼び出されるかが決まっている。
この点、finalメソッドもクラスメソッドもprivateメソッドと同様である。
実行時になってみないと呼び出すべきメソッドが決まらないpublic、protectedと、
コードの字面で決まるprivate、final、staticの違いは、
実験結果にもよくあらわれている。
また、動的呼び出しはこういったオーバヘッドがあるだけではなく、
JIT、AOTコンパイラによる各種最適化も制限してしまう。
例えば、実行時になってみないと呼び出すべきメソッドが決まらないため、
インライン展開が制限される。
インライン展開(inlining)とは、
呼び出し元メソッドの中に呼び出し先メソッドの処理を展開してしまうことで
メソッド呼び出しのオーバヘッドを削減するという、
コンパイラによる最適化のことである。
インライン展開の本当の一番のメリットは、
呼び出し元と呼び出し先をまたいでの大変な解析を行わずして、
呼び出し元、先をまたいで他の最適化を施せるという点である。
動的呼び出しに起因するこれらの問題は、
Javaに限らずオブジェクト指向言語に共通の古くからの問題なので、
多くの研究がなされてきた。
JavaのJIT、AOTコンパイラやインタプリタにもそれらの成果が採り入れられている。
ただし、Javaの性質から、既存のテクニックを単純には使えない場合も多い。
IBMのJITコンパイラは、クラス階層解析を行うことで
呼び出すべきメソッドをJITコンパイルの時点でなるべくひとつまでしぼろうとする。
メソッドがオーバライドされているか否かを解析するのである。
もし、実際に呼び出されるメソッドをひとつにまで見切ることができれば、
動的呼び出しの問題は回避できるわけである。
しかしここで、Javaのとある性質がこのテクニックの障害となる。
Javaでは、プログラムの実行中に、
必要となったクラスが順次JVM上に動的にロードされていく。
そのため、JITコンパイルの時点ではオーバライドされていないと判定できた
メソッドが、動的ロードによってオーバライドされてしまうかもしれない。
そこでIBMのJITコンパイラは、動的ロードによってメソッドがオーバライドされた
場合にはコンパイル結果のコードを書き換えて対処する。
このように、同期処理やメソッド呼び出しのコンパイル手法は
今もなお研究が盛んで、実行系の開発元ごとに差別化を図れる部分である。
Javaの実行系によって性能が異なったり、
新しい版で大きく性能が変わったりする部分なので、
Javaプログラマとしては手もとの環境での性能が普遍的なものだとは考えずに、
注意深く動向を観察していくことが必要だろう。
例外についてのコードの書き方、すなわち、try 〜 catch、
メソッドのthrows宣言、例外のthrowが、性能にどういった影響を与えるかを見ていく。
まず、Javaではtry 〜 catchを記述しただけではペナルティとはならないのが
普通である。
これは、例外に関する記述だけで性能が低下するC++とは異なる点である。
この記事で先にJavaの性質について述べた際に、
配列コピーの終了を繰り返し回数で判定するか、
範囲外アクセスの例外で判定するかを比較した。
例外を使った方法の(1)と(2)の違いは、(1)ではtry 〜 catchがループの外にあるが、
(2)ではループ内に書かれている点である。
もしtry 〜 catchの記述が何らかのペナルティとなるなら、
その分(2)の方が性能は悪くなるはずである。
しかし、実験結果は、インタプリタでは(1)、(2)の性能は同じで、
JITコンパイラを使った場合はJITの種類によって
優劣が入れ替わった。
IBMのJITでの結果は説明できていないが、少なくともそれ以外すべての実行系では、
try 〜 catchの記述はペナルティとはなっていない。
それに対して、例外のthrowはそれなりに重い処理である。
例外はjava.lang.Throwableクラスか、またはそのサブクラスのインスタンスなので、
例外がthrowされるとインスタンス生成が起こる。
コンパイラが生成を省いてくれる可能性はあるとはいえ、
あらゆる場合には期待できない。
また、例外がthrowされると、次にどこに実行を移したらよいのか決めるために
JVMは表を調べる。これも重い処理である。
これらのペナルティを削減するための最適化も考えられてはいるが、
実行系やコンパイラの開発者としては、
例外はあくまで例外的な状況にだけthrowされるのが普通だろう、と考えがちである。
ごくたまに例外的に使われる機能の高速化に力を注いでも効果は低いというのは、
この記事でも先に述べた通りである。
例外throw時の処理の高速化は、JVM、JIT開発者の間での優先順位は高くないので、
性能は期待できない。
try 〜 catchの使用は性能に影響を与えにくいとはいえ、
例外がプログラムの性能にまったく影響を与えないわけではない。
例外をthrowし得る処理がコード中にあるだけで、
JIT、AOTコンパイラによるある種の最適化は制限されてしまうのである。
プログラマにできることは、
例外をthrowする可能性のあるコードは書かないことだが、
残念ながらそれはほとんど無理である。
例えば次のコードがあったとする。
先に述べたクラスの動的ロードも含めて、Javaには、
JIT、AOTコンパイラによる最適化の障害となるこのような仕様や性質が数多くある。
仕様によっては、仕様の方を変更しようという動きもあるが、
厳しい仕様を満たしつつどこまで最適化できるかが
コンパイラ開発者のチャレンジとなっているのである。
ここで言及するのはJIT、AOTコンパイラではなく、
Javaプログラム(.java)をクラスファイル(.class)に変換する
Javaコンパイラである。
Javaコンパイラと言ってまず思い浮かぶのは、
JDKに含まれているjavacコマンドであろう。
世の中にはjavac以外にも多くのJavaコンパイラがある。
IBMのJikesは、C++で書かれた、
高速さと言語仕様への忠実さが特徴のJavaコンパイラである。
Kopi Java Compiler(KJC)はjavacと同様にJava言語自身で書かれた
Javaコンパイラで、TransVirtual社のJVM、
Kaffe 1.0.5のデフォルトのJavaコンパイラとなった。
コンパイラによって異なるのはコンパイルにかかる時間ばかりではない。
コンパイラの種類や版によって、
コンパイル結果のバイトコード命令列が異なってくる。
例を示そう。
Javaコンパイラが最適化を行わないことは別段問題にはならない場合も多い。
JIT、AOTコンパイラを使う場合は、インライン展開などの最適化はどうせ
JIT、AOTが行うので、
バイトコードの時点で最適化されていようがいまいが
性能には影響がないことが多いのである。
しかし、インタプリタや、コンパイルの速さを目標とした
あまり最適化を行わないJITコンパイラでは、
Javaコンパイラがどの程度の最適化を行ったかが性能に影響するだろう。
Javaプログラマとしては、
使うJavaコンパイラによって生成されるバイトコード命令列が違うことと、
それがインタプリタでの性能には影響を与える可能性があることを知っておきたい。
他にも、最適化のためのtipsは数限りなくある。
そのうち、どんなアプリケーションでも検討の価値があるものを
いくつか紹介する。
Javaで記述してあるメソッドをC、C++で書き直すのである。
CコンパイラがJIT、AOTコンパイラより質の良いコードを生成すれば速くなるだろう。
しかし、JITがインライン展開できなくなるなど、性能面で損する可能性もある。
また、アプレットでネイティブコードを使ってしまうと、
ブラウザさえ用意すればどこでも実行できるというメリットが消えてしまう。
得失それぞれをよく検討すべきである。
Javaで書かれたメソッドをCのネイティブメソッドに変換するタイプの
AOTコンパイラもあるので、そういったものを使う方法も考えられる。
プログラムの消費メモリを節約することで、
データがプロセッサのキャッシュに載るようになったり、
GCの頻度が減ったり、OSによるページング回数が減ったりして、
性能が向上する可能性がある。
プログラマとしてできることには、生成するインスタンスの削減や、
型の変更などがある。
例えば、int型の配列を使っていても、
もし値が-32768から32767の範囲に収まるならshort型に変更できる。
要素あたりの消費メモリが4バイトから2バイトと半分になり、メモリの節約となる。
ただし、整数の演算はJVM中ではint型で行われることが基本なので、
int型とshort型の変換が頻繁に必要になるかもしれない。
場合によっては、java.lang.Systemクラスのgc()メソッドを
プログラム中から呼ぶことも有効である。
gc()を呼ばなくともGCは走るので、本来はわざわざ呼ぶ必要はない。
しかし例えば、入力に対して素早く反応しないといけない局面で
GCが動いていては困るといった場合には、
余裕のあるうちにgc()を呼んでおくことで、
大事な局面でGCが動いている可能性を低くできるかもしれない。
もっともこの問題に対しては、
GCの実装方法で解決しようという努力がJVMの開発側で続けられている
(incremental GC)。
配列の内容をコピーする方法として最も基本的なのは次のコードであろう。
どちらの方法が速いかは主に配列の長さに依って決まる。
現在のところ、非常に大きな配列のコピーはarraycopy()の方が速いが、
短い配列ではarraycopy()を使わずにJavaで書いた方が速い。
どのくらいの長さで逆転が起こるかは、JVM、JIT、AOTコンパイラなどに
依存して決まるので、一概には言えない。
ひとつ言えるのは、Javaで書いた方は今後のJIT、AOTコンパイラによって
速くなる可能性があるが、ネイティブメソッドの方が速くなる可能性は低い
ということである。
ネイティブメソッドで使われるCコンパイラ、ライブラリにおいて、
配列コピーに関する進歩は期待できないからである。
この記事の先頭の方で例を挙げたように、OSの入出力機能を利用する場合は、
バッファ、つまりBufferedOutputStreamおよびBufferedInputStreamのインスタンスを
用意することが非常に有効である。
先の例では実行時間が1/27に短縮された。
OSの機能を直接呼ぶ回数を減らすためのテクニックである。
OSの入出力機能とは例えばファイル入出力や、ネットワーク経由の通信が該当する。
また、バッファの大きさを変更すると入出力性能、スループットが変わる。
あまり小さいとバッファの意味がないし、逆に大きすぎると
プロセッサのキャッシュヒット率が下がって性能が下がる。
バッファの大きさはBufferedOutputStream、BufferedInputStreamクラスの
コンストラクタで指定できる。
調べたところ、デフォルトの大きさは、JDK 1.3、1.2.2、1.1.8では、
BufferedOutputStreamで512バイト、BufferedInputStreamで2048バイトとなっていた。
コードの書き方からははずれるが、JVMを起動する際のオプションは軽視できない。
SunのJDK 1.3であれば、HotSpot Client VMとServer VMの選択は
オプション(-hotspotと-server)で行うし、
HotSpot VMのセールスポイントのひとつであるincremental GCは
-Xincgcオプションを付けないと有効にならない。
オプションの中でも特に、どんなプログラマにも関係が深いのは
ヒープサイズの指定である。
ヒープとはインスタンスが置かれる領域のことで、
例えば、-Xmx128m -Xms32mという指定は、初期ヒープサイズを32MBに、
最大ヒープサイズを128MBにするという意味である。
ヒープサイズの設定は、もちろん、
どれだけたくさんのインスタンスを生成できるかを決めるが、それだけではない。
最大ヒープサイズが大きすぎると、ヒープ全体がメモリに載らずに
ディスクへの書き出し(ページング)が起きてしまいかねない(図9)。
これが起きると、プログラム性能は大きく低下する。
それならむしろ、メモリから溢れる前にGCが走った方がましである。
ヒープをメモリに載せ続けるためには、
最大ヒープサイズをメモリの量より少ない適当な値に設定する必要がある。
最適な設定は、JVMと同時に走るOSや他のプログラムが
どのくらいのメモリを消費するかに依るだろう。
また、最大ヒープサイズを指定しなかった場合に一定の値にするのではなくて、
搭載メモリ量に応じて適当に設定してくれるJVMもある。
ここまで、最適化とは何かからはじまり、Javaに固有のtipsまで、
Javaプログラムの最適化に要求される理解や知識をひと通り眺めてきた。
こまごましたノウハウはたくさんあるものの、
最も普遍的ではずしてはならないのはアルゴリズムとデータ構造についての
理解である。
これによって、性能が根本的に変わってくる。
データ構造に関する理解とは例えば、目的の処理に対して
java.util.ArrayListとjava.util.LinkedListのどちらを使うべきかを
判断できる素養である。
次に、環境についてよく知ることである。
効率のよいコードを書くためには、コンピュータアーキテクチャ、
特にプロセッサやメモリ階層についての理解が欠かせない。
JVMを知ることももちろん役立つし、
コンパイラを知ることで、コードの書き方と性能の関係が見えてくる。
あとは、本当に性能を向上させたいなら、きちんと計測、
プロファイリングを行うことである。
Javaはまだ実行系の研究開発が盛んに行われている最中なので、
状況は刻々と変化し続けている。
過去の知識や結果に固執せずに柔軟に対応、判断することを心がけたい。
> java -Xrunhprof:help
と打つと表示されるヘルプメッセージを参照して欲しい。
4. Javaの性質
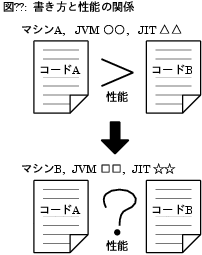
図3: 書き方と性能の関係
添字を使った方法:
また、普通はこうは書かないが、以下の方法もある。
範囲外の不正な添字で配列にアクセスした場合に発生する例外を利用している。
for (int i = 0; i < SIZE; i++) {
dst[i] = src[i];
}
例外を使った方法(1):
int i = 0;
try {
while (true) {
dst[i] = src[i];
i++;
}
}
catch (ArrayIndexOutOfBoundsException e) {}
例外を使った方法(2):
配列のサイズを16MBとして、
筆者の環境(Pentium II/333 MHz, Linux)で
上記3種類のコードの実行時間を計測した。
JITコンパイラの有無やJITの種類が性能にどう影響を与えるかを見ていく。
i = 0;
while (true) {
try {
dst[i] = src[i];
i++;
}
catch (ArrayIndexOutOfBoundsException e) {
break;
}
}
まずはIBM JDK 1.3での結果である。
表1の通りとなった。
ここで注目して欲しいのは、添字を使った方法と例外を使った方法(1),(2)の速さが、
JITコンパイラの有無によって入れ替わっていることである。
インタプリタでは例外を使った方法が速いが、
JITコンパイラでは添字を使った方が速い。
表1: IBM JDK 1.3での実行時間 (ミリ秒)
添字 例外(1) 例外(2) JITコンパイラ 410 470 520 インタプリタ 4540 2570 2570
次にSun JDK 1.3での結果を見よう。表2の通りである。
IBM JDKとは異なり、JITコンパイラの有無で性能が逆転していることはない。
しかし、IBMのJITとSunのJITとを比較すると、
添字を使った方法と例外を使った方法(2)の結果が逆転している。
表2: Sun JDK 1.3での実行時間 (ミリ秒)
添字 例外(1) 例外(2) JITコンパイラ 780 780 740 インタプリタ 4810 3550 3500
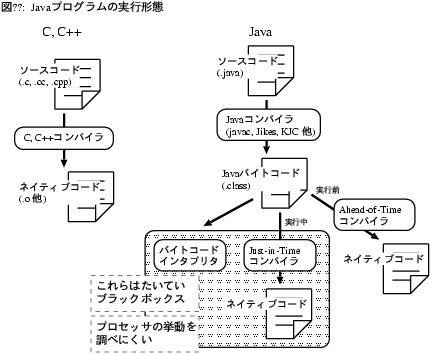
図4: Javaプログラムの実行形態
5. Javaの特徴に応じた最適化
最適化に関するJavaの性質を述べてきた。
ここからは、より詳細に、Javaの特徴とそれに応じた最適化の指針を見ていく。
想定する環境はやはりPC程度より大きいコンピュータで、
主にJVM上でのJITコンパイラを用いての実行を想定する。
もちろんJITの有無に依らない内容も多いし、
AOTコンパイラにもほぼすべて通用する。
インスタンスの生成
synchronizedを使って次のように書き換える。
void aMethod() {
byte[] buffer = new byte[SIZE];
bufferを使った目的の処理
}
配列(buffer[])をインスタンス変数からクラス変数に変更することで、
生成の回数をプログラムの実行につき1回にまで削減できた。
ただし、生成した配列を全スレッドで共有して使い回すことになるので、
メソッドをsynchronizedとした。
このsynchronizedによる同期のコストは増えるが、
インスタンス生成の方が重いことが少なくとも現在は一般的なので、
たいていは速くなる。
static byte[] buffer = new byte[SIZE];
synchronized void aMethod() {
bufferを使った目的の処理
}
配列アクセス
あり得ない。
もしJIT、AOTコンパイラがそこまで解析してくれれば、
境界チェックは省かれるかもしれない。
しかし、もし上のコード中の変数sizeがローカル変数ではなく
インスタンス変数またはスタティック変数だったらどうだろうか。
他のスレッドから変更される可能性がうまれる。
forループの実行中にもし他のスレッドがsizeの値を増やしたとすると、
iの値が配列サイズ以上になって例外が発生するかもしれない。
その危険がある以上、JIT、AOTコンパイラとしては
境界チェックを省くわけにはいかなくなる。
int size = ...;
int[] array = new int[size];
for (int i = 0; i < size; i++) {
array[i] = ...;
}
多次元配列の生成とアクセス
多次元配列についての処理が重いことには、
1次元配列のアクセスが重い以上の理由がある。
正確に言うとJavaに多次元配列はない。
2次元配列に見えるもの(a[][])は1次元配列の配列であり、
3次元配列に見えるもの(a[][][])は1次元配列の配列の配列である(図5)。
しかしここでは、便宜上、配列の配列…の配列を多次元配列と呼ぶ。
多次元配列は次のように生成できる。
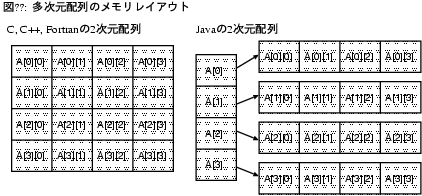
図5: 多次元配列のメモリレイアウト
これは、次のコードと等価である。
(厳密に言うと、ヒープの空き不足で例外が発生した場合の状態は異なる。)
int[][] array = new int[3][4];
つまり、4つのインスタンスが生成されている。
このように、多次元配列を生成するとただでさえ重いインスタンスの生成が
何度も行われることになる。
例えば、new int[5]、new int[5][5]、new int[5][5][5]では
それぞれいくつのインスタンスが生成されるだろうか?
答は、6、31、156である。new int[5][5][5][5]に至っては、
781ものインスタンスが生成される。
int[][] array = new int[3][];
array[0] = new int[4];
array[1] = new int[4];
array[2] = new int[4];
配列A,B,Cを2次元配列から1次元配列に書き換える。
for (i = 0; i < n; i++) {
for (j = 0; j < n; j++) {
double sum = 0;
for (k = 0; k < n; k++) {
sum += A[i][k] * B[k][j];
}
C[i][j] = sum;
}
}
行列のサイズnを500とした場合の、筆者の環境(IBM JDK 1.3)での
実行時間は次の通りである。
for (i = 0; i < n; i++) {
for (j = 0; j < n; j++) {
double sum = 0;
for (k = 0; k < n; k++) {
sum += A[n*i + k] * B[n*k + j];
}
C[n*i + j] = sum;
}
}
1次元配列に書き換えることで添字の計算のための
乗算と加算が増えているにも関わらず、実行時間は短くなった。
2次元配列 9.96 1次元配列 9.27 (秒) 変数の種類とアクセスコスト
int型変数i, n, sumが、ローカル変数、インスタンス変数、クラス変数
の場合に、それぞれ実行時間がどうなるかを計った。
なお、JITコンパイラによる最適化でループボディ(sum += i)の処理が
削除されてしまうことのないよう、
計測コードの後ろに変数sumを使用する文を書いた。
sum = 0;
for (i = 0; i < n; i++) {
sum += i;
}
表3: 変数アクセス (ミリ秒)
ローカル インスタンス クラス
IBM JITコンパイラ 620 920 1220 IBM インタプリタ 19370 47450 49850 Sun JITコンパイラ 2120 2470 2740 Sun インタプリタ 20460 63170 47230
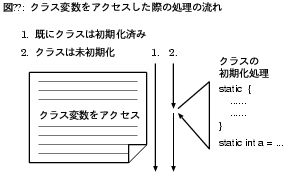
図6: クラス変数をアクセスした際の処理の流れ
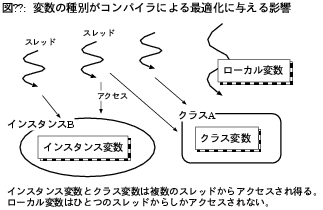
図7: 変数の種別がコンパイラによる最適化に与える影響
ここで注意して欲しいのは、VectorクラスのaddEleemnt()メソッドは
synchronizedメソッドだということである。
そのため、このコードを実行するスレッドは、
addElement()を呼び出すたびにVectorのインスタンスの
ロックを取得し、呼び出しから戻る際に解放する。
しかし、このロックの取得、解放は実は必要ではない。
vecはローカル変数なので、
vecが指すインスタンスを他のスレッドが参照することはあり得ないからである。
複数のスレッドがVectorのインスタンスを操作してしまうことを
防ぐことが目的のロックなので、
ひとつのスレッドからしか参照できないことが明らかな
インスタンスをロックしても無駄である。
JIT、AOTコンパイラがこの無駄なロックを省いてくれることは
充分に考えられる。
Vector vec = new Vector();
……
vec.addElement(…);
vec.addElement(…);
vec.addElement(…);
……
同期処理
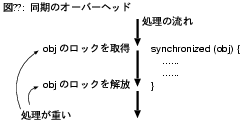
図8: 同期のオーバーヘッド
次のように、複数回の同期を一度にまとめてしまうのである。
synchronized (obj) { 処理A }
処理B
synchronized (obj) { 処理C }
処理A,B,Cを含むメソッド自体をsynchronizedにしてしまう方法も考えられる。
ただしこの方法は、同期のコストを削減する代わりに、
ロックを長時間保持し続けることで
他のスレッドが動作するチャンスを奪いかねないということは
知っておくべきである。
また、上記の例では、本来は排他制御する必要のない処理Bについても
ロックを保持したまま処理するので、
コードを見た別のプログラマが、排他制御が必要なものと勘違いする危険もある。
synchronized (obj) {
処理A
処理B
処理C
}
メソッドのアクセス制御と呼び出しコスト
呼び出し側のコードは次の通りである。
int callee(int value) {
return value + 1;
}
メソッドcalleeのアクセス修飾子をさまざまに変え、
筆者の環境でIBM JDK 1.3とSun JDK 1.3で実験した結果が表4である。
表中でstaticとあるのはpublic static、
finalとあるのはpublic finalとした場合の結果である。
また、interfaceとあるのは、
interface経由でpublicメソッドを呼び出した際の結果である。
int n = 30000000;
int sum = 0;
for (int i = 0; i < n; i++) {
sum += callee(i);
}
表4: メソッド呼び出し (ミリ秒)
public protected private final static interface IBM JITコンパイラ 840 840 380 380 380 380 IBM インタプリタ 20030 20020 18680 20040 15100 20000 Sun JITコンパイラ 1550 1720 380 450 350 1540 Sun インタプリタ 16160 16160 15890 15890 14800 17150 例外に関するコスト
プロセッサを効率よく動かすために、JIT、AOTコンパイラとしては
処理Cの一部を処理Bの前に移動させたいという状況はよくある。
しかし、Java言語の仕様では、処理Bが例外をthrowした場合に
処理Cの一部がすでに行われてしまっているということは許されない。
そのため、コードの移動がかなり制限される。
困ったことに、例外をthrowし得る処理は何もthrowと書かれたコードだけではなく、
どんなJavaプログラムの中にも溢れている。
インスタンス変数のアクセスはNullPointerExceptionをthrowし得るし、
配列の要素アクセスはArrayIndexOutOfBoundsExceptionを発生させる可能性がある。
メソッドを呼び出すと、そのメソッドの中から例外がthrowされてくるかもしれない。
処理A
例外をthrowするかもしれない処理B
処理C
Javaコンパイラの違い
メソッドcaller()がcallee()を呼び出している。
privateメソッドであるcallee()がオーバライドされることはあり得ないので、
Javaコンパイラはcallee()の処理をcaller()中に
インライン展開してしまっても問題はない。
各種Javaコンパイラがこの最適化を行うかどうか調べたところ、
JDK 1.1.8のjavacだけが行い、JDK 1.2.2と1.3のjavac、およびJikes 1.0.5は
行わなかった。
定数伝搬など他の最適化手法2、3についても調べたところ、
インライン展開と同じ結果となった。
class InliningTest {
public void caller() {
System.out.println(callee());
}
private int callee() {
return 5;
}
}
6. その他の最適化
ネイティブメソッド化
メモリの節約
Systemクラスのarraycopy()メソッド
配列のコピーには、専用のメソッドも用意されている。
それを使うと次のように書ける。
int[] src, dst;
…
for (int i = 0; i < n; i++) {
dst[i] = src[i];
}
このarraycopy()メソッドは、(少なくともJDK 1.3までは)
ネイティブメソッドである。
System.arraycopy(src, 0, dst, 0, n);
入出力のバッファリング
JVM起動時のオプションとパラメタ
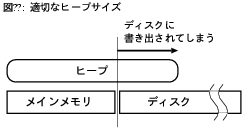
図9: 適切なヒープサイズ
7. まとめ